WichtigEmpfehlung zum Arbeiten mit dieser Einführung in die EDA
Wir wollen sofort hands-on EDA in dieser Einführung beginnen. Sie sollen nicht nur passiv die Aufgabenstellungen nachvollziehen, sondern dies sowohl durch Verständnisfragen reflektieren, als auch erste Schritte mit R gehen. Laden Sie deshalb das csv-File production_data.csv aus Moodle (direkt unter diesem Moodle-Buch) und importieren Sie es parallel, wenn wir dies hier machen, in ihr eigenes R Skript (oder Quarto Dokument, *.qmd, ähnlich wie Jupyter-Notebooks) in RStudio. Kopieren Sie dann schrittweise den jeweiligen Code-Chunk in das R Scrip und lösen auch die ersten Aufgabenstellungen mit der EDA.
Wir wollen mit dieser Einführung in die EDA so schnell wie möglich mit der Praxis der Statistik in Berührung kommen, d.h. wir werden, motiviert durch eine praktische Fragestellung, die notwendige Theorie on-demand erarbeiten, wo wir sie in der Explorativen Datenanalyse benötigen. So sehen wir sofort, warum Sie kein Zierwerk, sondern solide Basis seriösen wissenschaftlichen Arbeitens in der Statistik ist. Dieser Ansatz ist anspruchsvoll und die Lernkurve am Anfang etwas steiler, dafür sehen wir sofort, warum Dinge relevant sind! Dies gilt nicht nur für die theoretischen Grundlagen, sondern auch die ersten Schritte in R und dem sog. tidyverse, die wir sowohl für die Datenaufbereitung, wie auch die Datenvisualisierung benötigen.
Was versteht man unter Explorativer Datenanalyse?
In modernen datengetriebenen Unternehmen entstehen täglich riesige Datenmengen. Doch Daten allein erzeugen noch keinen Wert. Erst die Fähigkeit, aus ihnen strukturiertes Wissen abzuleiten, macht sie wirtschaftlich und technisch relevant. Genau hier setzt die Explorative Datenanalyse (Exploratory Data Analysis, EDA) an.
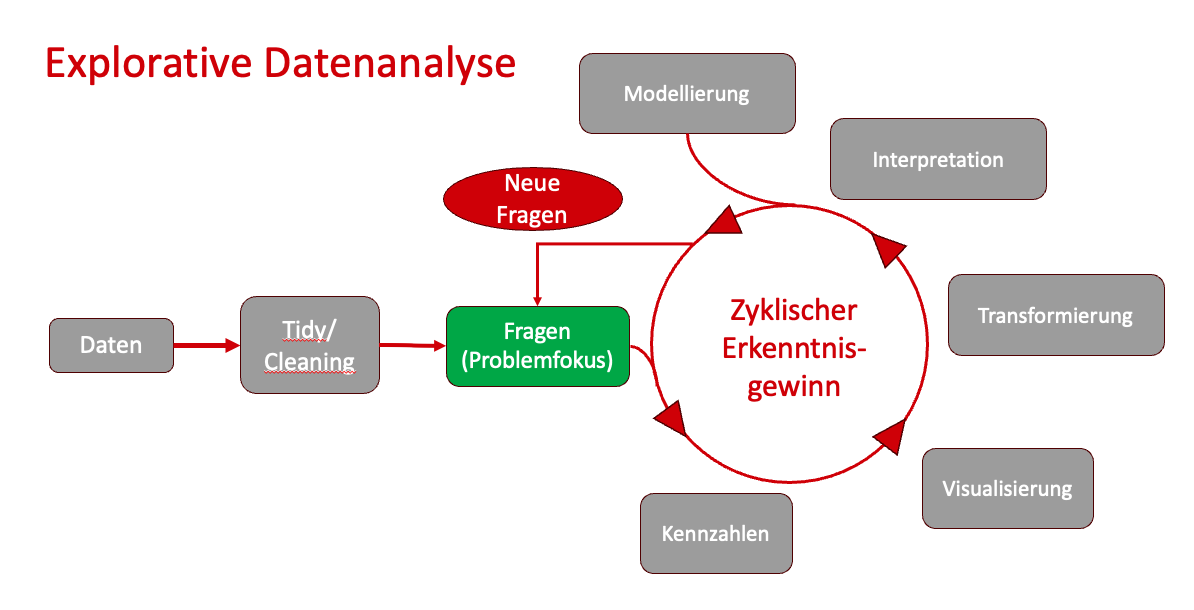
Bevor Modelle entwickelt, Kennzahlen berichtet und Entscheidungen getroffen werden, braucht jedes datenbasierte Projekt eine Phase, in der die Daten verstanden, geprüft und erforscht werden. Die EDA ist hierbei wie ein erster „Rohschnitt“ eines Analyseprojekts: Eine kreative Phase, in der Muster entdeckt, Ideen ausprobiert, Datenprobleme sichtbar gemacht und vielversprechende Spuren identifiziert werden. Erst dieser Rohschnitt zeigt, welche Fragen sich tatsächlich sinnvoll beantworten lassen und welche nicht. Die EDA ist hierbei kein einziger grosser Wurf, sondern eine zyklische Abfolge von Fragen stellen, Kennzahlen bestimmen, visualisieren, transformieren, interpretieren und wieder neue Fragen stellen bis hin zu Modellierung und dem Machine Learning. Das nachfolgende Schema visualisiert diesen zyklischen Charakter der EDA nochmals:
Mit dieser Einleitung in die EDA und Deskriptive Statistik verfolgen wir folgende Ziele:
Motivation
Sie sollen verstehen, warum die EDA die Grundlage aller datenorientierten Entscheidungen und Modelle bildet – und warum selbst modernste Methoden im Machine Learning ohne eine sorgfältige EDA leicht zu Fehlinterpretationen führen können.
Grundidee und Ablauf der EDA
Sie lernen den typischen Workflow der EDA kennen und sehen an einem konkreten Beispiel, wie Kennzahlen, einfache Visualisierungen und Korrelationen genutzt werden, um zentrale Fragen an Daten zu beantworten.
Theoretische und konzeptionelle Grundlagen
Die notwendigen theoretischen und konzeptionellen Grundlagen die wir aus der deskriptiven Statistik für die EDA benötigen.
Die EDA ist damit nicht nur der erste Schritt in der Datenanalyse, sondern auch die grosse Klammer, die den gesamten Kursinhalt überspannt. Alle statistischen Theorien und Methodiken, die wir in diesem und den nachfolgenden Blöcken kennenlernen, dienen dem Erkenntnisgewinn aus Daten. Um dies mit Leben zu füllen schauen wir uns ein konkretes einfaches erstes Beispiel an und erarbeiten uns daran bereits erste wichtige Begriffe, Metriken/Kennzahlen und Visualisierungen um Daten zu beschreiben.
Einführendes Beispiel in die EDA und deskriptive Statistik
Im nachfolgenden Beispiel wollen wir die EDA bereits in Aktion sehen. Hierfür haben wir ein Beispiel aus der Prozessanalytik der Fertigung in einem KMU, welches metallische Kleinbauteile für die Automobilindustrie fertig, ausgewählt.
In diesem automatisierten Produktionsprozess werden täglich hunderte identische Werkstücke hergestellt. Während der Fertigung eines Werkstücks messen eine Vielzahl von Sensoren im System verschiedene Prozessgrössen, unter anderem:
wie stark die Maschine ausgelastet ist,
wie warm ist die Maschine während des Herstellungsprozesses,
wie lange der Produktionszyklus eines Werkstücks dauert,
auf welcher Maschine und in welcher Schicht produziert wurde.
Diese Daten werden automatisch gespeichert und stehen für Analysen zur Verfügung. In letzter Zeit ist dem Qualitätsmanagement aufgefallen, dass manche Werkstücke deutlich längere Produktionszeiten besitzen als andere.
Unser Datensatz enthält eine Beobachtung pro produziertem Werkstück mit folgenden Variablen/Merkmalen aus dem Zeitraum vom 1.2.2024-3.2.2024:
Variable
Typ
Bedeutung
Timestamp
Zeitstempel
Zeitpunkt der Produktion (im 5-Minuten-Abstand)
MachineID
kategorial
Kennung der Maschine (M1–M8)
MachineType
kategorial
Maschinentyp, A oder B
Shift
kategorial
Produktionsschicht: Morning, Evening, Night
Load
numerisch
Maschinenauslastung in %
Temperature
numerisch
Maschinentemperatur in °C
CycleTime
numerisch
Produktionszeit eines Werkstücks in Sekunden
Anm.: Unter Maschinenauslastung in % verstehen wir, dass eine Maschine vorgefertigte Teil angeliefert bekommt und bei 100% permanent ohne Pausen arbeitet. Werden mehr Teile angeliefert, als sie verarbeiten kann treten Wartezeiten auf Die EDA startet für uns schon bei der allerersten Information über die Daten. Bevor wir mit einem Aufräumen oder gar Analyse der Daten starten können, müssen wir zuerst verstehen woher die Daten kommen und wie sie systematisch beschrieben werden.
Woher kommen die Daten, wie gelangt man an sie und woraus bestehen sie?
Hierfür brauchen wir eine Art Alphabetisierung mit einigen statistischen Grundbegriffen um deren Definitionen und Bedeutungen zu kennen. Ein kurzer Überblick:
Daten bestehen aus Objekte, auf die sich eine statistische Untersuchung bezieht – an ihnen werden Daten erhoben. Ein typisches Objekt oder Merkmalsträger ist z.B. eine Person, ihr Alter, Adresse, Gewicht, Grösse.
Woher kommen die Daten? Die Grundgesamtheit (Population)
Die Menge aller für eine Fragestellung interessierenden statistischen Einheiten. Entscheidend ist: Sie muss klar abgegrenzt sein (z. B. Zeitraum, Ort, Prozess, Produkttyp). Man betrachtet z.B. eine Altersgruppe in einer bestimmten Region.
Merkmal / Variable
Eine Eigenschaft der statistischen Einheiten/Objekt (z. B. “Alter”,“Körpergrösse”).
Welche Eigenschaften haben Objekte? Die Merkmalsausprägungen
Die möglichen Werte, die ein Merkmal annehmen kann (z.B. Zahlenwert der Körpergrösse oder Kategorien wie das Geschlecht).
Wie gelangen wir an die Daten: Die Stichprobe
Wählt man aus einer Grundgesamtheit nach einem Auswahlverfahren eine Teilmenge, spricht man von einer Stichprobe. z.B. können wir nicht alle Männer im Kanton Zürich auf die Waage stellen um ihr Gewicht zu bestimmen.
Direkt nach dem Ziehen der Stichprobe: Urwerte / Primärdaten / Rohdaten
Das sind die beobachteten Werte eines Merkmals in Grundgesamtheit oder Stichprobe. Fasst man alle Urwerte in einer Liste zusammen, erhält man eine Urliste. Von Rohdaten sprechen wir, bevor wir irgendeine Modifikation vorgenommen haben, sie liegen nach einer Messung oder der Erhebung eines Fragebogens vor.
Diese Begriffe müssen wir kennen, um statistische Literatur später lesen zu können. Wenden wir sie gleich an.
HinweisAufgabe: Wenden Sie die Grundbegriffe auf unsere Produktionsdaten an
Beantworte die folgenden Fragen in ganzen Sätzen (stichwortartig reicht, aber sauber formuliert) und vergleichen Sie mit den Musterantworten:
Statistische Einheit / Merkmalsträger (Objekt):
Was ist in unserem Datensatz ein einzelnes „Objekt“?
Grundgesamtheit (Population):
Formuliere eine klar abgegrenzte Grundgesamtheit für unsere Fragestellung. Hinweis: Nenne mindestens Produkttyp + Produktionsprozess/Ort + Zeitraum.
Stichprobe:
Was ist in unserem Beispiel die Stichprobe?
Merkmale und Merkmalsausprägungen:
Wähle zwei Merkmale/Variablen aus der Tabelle (z. B. Shift, MachineType, CycleTime) und notiere je zwei konkrete Ausprägungen.
Musterlösung anzeigen
Statistische Einheit: Ein einzelnes produziertes Werkstück (eine Zeile im Datensatz, inkl. seiner Messwerte).
Grundgesamtheit: Alle Werkstücke dieses Produkttyps, die im betrachteten Zeitraum in diesem Produktionsprozess (diesem Werk/dieser Fertigungslinie) produziert werden.
Stichprobe: Die im Datensatz enthaltenen Werkstücke (z. B. die 600 protokollierten Werkstücke).
Beispiele:
Merkmal Shift → Ausprägungen: Morning, Night
Merkmal MachineType → Ausprägungen: A, B
Merkmal CycleTime → Ausprägungen: z. B. 78 s, 412 s (konkrete Urwerte)
Jetzt verstehen wir, woher die Daten kommen, aber wenn wir die Übersicht über die Merkmale/Variablen ansehen, sehen wir Datentypen, wie numerisch oder kategorial (engl. factor) die wir noch nicht kennen. Ihre Verschiedenheit in den sog. Skalenniveaus müssen wir verstehen, den diese hat weitreichende Konsequenzen, welche Art Analysen oder Visualisierungen wir mit ihnen durchführen können.
Datentypen, Merkmalsausprägungen und Skalenniveaus
Merkmale/Variablen unterscheiden sich teilweise erheblich. Das Merkmal Farbe einer PKW-Serie kennt nur Merkmalsausprägungen wie „rot, grün, blau“. Hingegen die Leistung des Motors in PS wir numerisch angegeben (z. B. 180 PS). Lassen wir uns im nachfolgenden Video kurz einen Überblick dazu geben.
Fassen wir diese neuen Begriffe zusammen:
WichtigMerkmalsausprägungen & Skalenniveaus
Skalenniveaus (Messskala) – was ist „sinnvoll“ zu rechnen?
Mittag unterscheidet drei zentrale Skalenniveaus: Nominal, Ordinal und metrisch.
Nominalskala: Kategorien ohne natürliche Ordnung, z.B. Farben, Geschlecht etc. → Differenzen/Quotienten nicht sinnvoll.
Ordinalskala: Rangordnung, aber Abstände nicht vergleichbar, z.B. Ranglisten im Sport → Differenzen/Quotienten nicht sinnvoll.
Metrische Skala: Abstände interpretierbar.
Intervallskala: kein natürlicher Nullpunkt (z. B. °C im Gegensatz zu K (Kelvin mit absolutem Nullpunkt)) → Quotienten nicht sinnvoll.
Verhältnisskala: natürlicher Nullpunkt, z.B. Körpergewicht (negativer Wert nicht sinnvoll); Kelvintemperaturskala → Quotienten sinnvoll (z. B. Zeit).
Absolutskala: Sonderfall mit natürlicher Einheit (z. B. Anzahl).
Merksatz: Das Skalenniveau entscheidet, welche Operationen (zählen, ordnen, Differenzen, Quotienten) sinnvoll interpretierbar werden können für ein Merkmal/Variable.
Dies wollen wir wieder direkt auf unsere Beispiel anwenden:
HinweisAufgabe: Zuordnung des Datentyps und der Skalenniveaus auf unsere Produktionsdaten
Ordne für jede Variable (a) Typ und (b) Skalenniveau
Temperature: numerisch → metrisch (oft Intervall bei °C)
CycleTime: numerisch → metrisch (Verhältnis)
Timestamp: Zeitvariable → Zeitindex
Jetzt verstehen wir die Angaben, die wir zu unseren Daten bekommen haben! Unsere Messwerte kommen aus einer Grundgesamtheit. Hier ist es jedoch keine Bevölkerung, die bestimmte Eigenschaften besitzen, sondern die Produktionsmaschine! Immer wenn wir einen Messwert erfassen, ist dies eine Stichprobe des Verhaltens der Maschine und damit der Grundgesamtheit. Kategorial sind jene Merkmale/Variablen in den Daten, wie MachineID oder Shift die keine numerischen Messwerte besitzen, sondern nur Bezeichnungen oder Zuordnungen zu Kategorien (Nachschicht, Tagschicht, etc.). Sie sind qualitativer Natur. Allerdings können sie auch eine Ordnung besitzten, wie z.B. Schulnoten. Wir behalten im Hinterkopf, dass es sicherlich nicht sinnvoll sein wird einen Mittelwert aus einer MachineID zu berechnen! Wir gehen weiter.
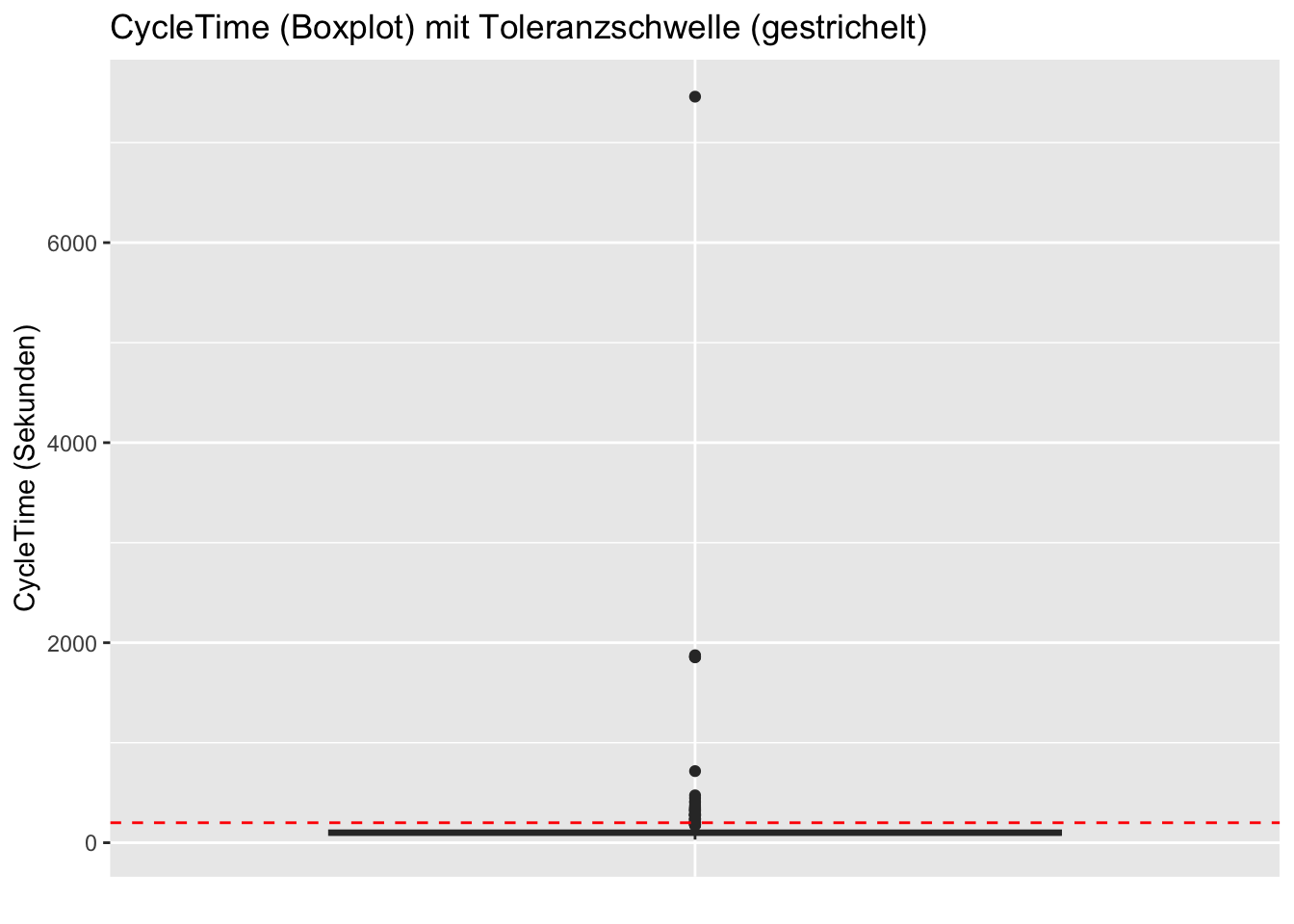
Die Leiterin der Qualitätssicherung kommt zu uns mit der Feststellung, dass ~7.3% der Fertigungsteile eine Fertigungszeit (CycleTime) über dem Limit von 200 s besitzen. Sie zeigt uns einen kurzen Ausschnitt der Daten und ein Diagramm, das sie Boxplot nennt und gibt uns einen Auftrag.
Erste Forschungsfrage: Wie hängen die ungewöhnlich langen Produktionszeiten von den wichtigsten Prozessgrössen ab und wie kann man sie ggf. reduzieren?
Import der Daten und erste Übersicht
Wir machen uns an die Arbeit und importieren und sichten die Daten.
Timestamp MachineID MachineType Shift
Length:600 Length:600 Length:600 Length:600
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
Load Temperature CycleTime
Min. : -5.00 Min. : 15.70 Min. : 31.24
1st Qu.: 48.04 1st Qu.: 20.60 1st Qu.: 82.21
Median : 59.76 Median : 22.00 Median : 98.89
Mean : 59.24 Mean : 22.94 Mean : 135.79
3rd Qu.: 70.43 3rd Qu.: 23.40 3rd Qu.: 119.10
Max. :135.00 Max. :200.00 Max. :7459.49
NA's :25 NA's :15
Was fällt bei unseren Daten auf?
Timestamp, MachineType, MachineID, Shift werden als Wörter (charakters oder strings) importiert.
In der Variablen Load fehlen 25 Werte, Temperatur 15 (NA = Not available).
Negative Werte für Load
Datenreinigung/“Aufräumen” (tidy)
Wie können wir diese Anomalien und Unzulänglichkeiten in unseren Daten bereinigen? Hierfür verwenden wir die moderne Datenreinigungsbibliothek dplyr. Damit wir grob dem Code folgen können, schauen wir uns nur kurz die Logik hinter den pipelines von dplyr und die wichtigsten Befehle an, die wir verwenden. Die Ausführlichere Behandlung behalten wir in einem Tutorial in der Nachbereitung zu dieser Einführung.
Kurzüberblick der dplyrPipelines zum Aufräumen der Daten
TippKurzüberblick: dplyr-Pipelines (“Pipes”) und die wichtigsten Befehle
Die Grundidee: Wir lesen die Datenreinigung als Abfolge von Schritten – von links nach rechts.
Pipe %>%: Nimmt das Ergebnis links und gibt es als erstes Argument an die Funktion rechts weiter.
→ Dadurch wirkt Code wie ein „Arbeitsablauf“: Daten → Schritt 1 → Schritt 2 → …
Wichtig:dplyr verändert Daten nicht automatisch „in place“.
Wenn du das Ergebnis behalten willst, musst du es wieder zuweisen: production_data <- production_data %>% ...
Befehle, die wir gleich verwenden:
mutate(...): Spalten verändern/neu erstellen (z. B. Werte ersetzen, neue Variablen berechnen).
across(c(...), FUN): Wendet eine Funktion auf mehrere Spalten gleichzeitig an (z. B. as.factor).
ifelse(Bedingung, dann, sonst): Bedingtes Ersetzen, z.
negative Werte zu NA.
recode(Spalte, "alt" = "neu"): Tippfehler/Labels korrigieren durch Wert-Mapping.
count(Spalte): Zählt Häufigkeiten der Ausprägungen (praktisch zum Prüfen nach dem recode).
drop_na(): Entfernt alle Zeilen mit fehlenden Werten (NA) – ergibt einen „sauberen“ EDA-Datensatz.
summary(...): Schneller Plausibilitätscheck (Typen, Min/Max, Anzahl NAs, Levels bei Faktoren).
WarnungDaten reinigen und aufräumen (Data cleaning/wrangling)
Der nachfolgende Teil des aufräumens und reinigens ist oft zeitaufwendig und ermüdend, aber notwendig! Die Faszination der Datenanalyse ist nur mit dieser sauber und gründlich durchgeführten Phase möglich. Auch ihre ganzen schönen Machine Learning Algorithmen laufen nicht ohne sie, vergessen Sie dies nicht, wenn es auf dem Weg dort hin an der Motivation fehlt.
Was ist zu tun? Wir müssen die Typen der Variablen anpassen, in dem wir R genau sagen, welche Typen wir erwarten. Negative Werte beim `Load` setzen wir auf NA (not available).
Timestamp MachineID MachineType Shift Load
Length:600 M2 : 79 A:294 Evening:192 Min. : 0.9163
Class :character M7 : 79 B:306 Morning:216 1st Qu.: 48.4180
Mode :character M1 : 78 Night :177 Median : 59.8863
M5 : 78 Nigt : 15 Mean : 59.8070
M6 : 76 3rd Qu.: 70.4505
M8 : 73 Max. :135.0000
(Other):137 NA's :30
Temperature CycleTime
Min. : 15.70 Min. : 31.24
1st Qu.: 20.60 1st Qu.: 82.21
Median : 22.00 Median : 98.89
Mean : 22.94 Mean : 135.79
3rd Qu.: 23.40 3rd Qu.: 119.10
Max. :200.00 Max. :7459.49
NA's :15
Jetzt sehen wir, dass sie sog. kategorialen Variablen sind, wie wir es erwartet haben. Beider Variablen Shift finden wir 15 Tippfehler: Ngt, statt Night.
Nächster Schritt:
Tippfehler korrigieren
Timestamp in das richtige Format übertragen.
Fehlende Daten anschauen
Code
production_data <- production_data %>%mutate(Shift = dplyr::recode(Shift, "Nigt"="Night") )production_data %>%count(Shift) #Hier zählen wir alle Ausprägungen von Shift und Ngt sollte verschwunden sein.
Shift n
1 Evening 192
2 Morning 216
3 Night 192
Code
# Umwandung in eine kategoriale Variable; R identifiziert die "levels" von selbstproduction_data <- production_data %>%mutate(across(c(MachineID, MachineType, Shift), as.factor),Timestamp =as.POSIXct(Timestamp, format ="%Y-%m-%d %H:%M:%S") )# Formatanpassung für das Datumsformatsummary(production_data)
Timestamp MachineID MachineType Shift
Min. :2024-01-01 06:00:00 M2 : 79 A:294 Evening:192
1st Qu.:2024-01-01 18:26:15 M7 : 79 B:306 Morning:216
Median :2024-01-02 06:57:30 M1 : 78 Night :192
Mean :2024-01-02 06:56:29 M5 : 78
3rd Qu.:2024-01-02 19:23:45 M6 : 76
Max. :2024-01-03 07:55:00 M8 : 73
NA's :2 (Other):137
Load Temperature CycleTime
Min. : 0.9163 Min. : 15.70 Min. : 31.24
1st Qu.: 48.4180 1st Qu.: 20.60 1st Qu.: 82.21
Median : 59.8863 Median : 22.00 Median : 98.89
Mean : 59.8070 Mean : 22.94 Mean : 135.79
3rd Qu.: 70.4505 3rd Qu.: 23.40 3rd Qu.: 119.10
Max. :135.0000 Max. :200.00 Max. :7459.49
NA's :30 NA's :15
Auch bei Timestamp fehlen zwei Werte.
Was macht man mit fehlenden Werten? Sie treten auf, weil z.B. ein Sensor ausfällt oder ein Messwert nicht gespeichert wurde. Die radikale Methode besteht darin, alle Datenpunkte mit Lücken zu verwerfen. Das ist aber oftmals gleichbedeutend mit dem Verlust grosser Informationsmengen und nicht erwünscht.
Wie sieht es bei uns aus? Es fehlen gerade einmal 30 von 600, d.h. 5%. Das ist nicht ideal, aber meist vertretbar. Wir generieren einen neuen Datensatz, der alle NAs ausblendet, d.h. alle Zeilen im Dataframe gelöscht hat.
Timestamp MachineID MachineType Shift
Min. :2024-01-01 06:00:00 M1 : 76 A:272 Evening:180
1st Qu.:2024-01-01 18:20:00 M7 : 76 B:281 Morning:200
Median :2024-01-02 07:00:00 M5 : 75 Night :173
Mean :2024-01-02 06:58:19 M2 : 71
3rd Qu.:2024-01-02 19:25:00 M6 : 67
Max. :2024-01-03 07:55:00 M3 : 63
(Other):125
Load Temperature CycleTime
Min. : 0.9163 Min. : 15.70 Min. : 33.74
1st Qu.: 48.3825 1st Qu.: 20.60 1st Qu.: 82.74
Median : 59.8028 Median : 22.00 Median : 98.93
Mean : 59.7205 Mean : 22.67 Mean : 138.22
3rd Qu.: 70.4143 3rd Qu.: 23.40 3rd Qu.: 119.07
Max. :135.0000 Max. :200.00 Max. :7459.49
Wir haben es geschafft! Die Daten sind soweit aufbereitet und gereinigt, dass wir mit der EDA richtig loslegen können.
Visualisierungen
Bevor wir mit den Visualisierungen versuchen neue Einblicke in die Eigenschaften unserer Daten zu schaffen, brauchen wir wieder Handwerkszeug, diesmal über ggplot2 um dem R code folgen zu können. Auch hier holen wir die Detail gründlicher in einer Nachbereitung nach.
Kurzüberblick zum Plotten mit ggplot2
Tippggplot2 – Grammatik der Grafiken (wie man den Code „liest“)
Die Grundidee:ggplot2 baut eine Grafik schichtweise auf – wie ein transparentes Folien-Overlay.
Man startet mit Daten + Zuordnung (aes) und fügst dann Geometrien (Punkte, Balken, Boxen …) und Optionen (Skalen, Labels, Theme) als Layers hinzu.
1) Der „Kern“: Daten + Aesthetics (aes) - ggplot(data, aes(...)) definiert: - welcher Datensatz verwendet wird (data) - welche Variablen auf welche grafischen Rollen abgebildet werden (aes)
Typische Zuordnungen in aes(...): - x = ... / y = ... → Achsen - color = ... → Linien-/Punktfarbe (nach Kategorie oder Wert) - fill = ... → Flächenfüllung (z. B. Balken, Boxen) - group = ... → Gruppierung (wichtig bei Linien/Boxplots) - alpha = ... / size = ... → Transparenz / Grösse (selten als Mapping nötig)
Wichtig:
- Mapping gehört in aes(...) (wenn eine Variable etwas steuert).
- Konstante Einstellungen gehören ausserhalb von aes(...) (z. B. alpha = 0.4 für alle Punkte).
** 2) Die „Layers“: Geometrien (geom_*) Eine Grafik wird erst sichtbar, wenn du mindestens eine Geometrie** hinzufügst:
Du „liest“ den Code dann so: > Grundplot (Daten + aes)
> + eine Geometrie (wie wird gezeichnet?)
> + weitere Layer (z. B. Referenzlinien, Facets, Labels)
3) Statistiken unter der Haube (stat) Viele Geoms berechnen intern etwas: - geom_histogram() → zählt Werte in Bins - geom_boxplot() → berechnet Quartile, IQR, Ausreisser-Regel - geom_bar() → zählt Kategorien (wenn nur x gegeben ist)
Das ist wichtig, weil: Manchmal plotten wir nicht Rohdaten, sondern eine Zusammenfassung, die ggplot intern berechnet.
4) Skalen & Koordinaten: „Zoom“ vs. „abschneiden“ - coord_cartesian(ylim = ..., xlim = ...) → Zoomt, ohne Daten zu entfernen (empfohlen zum „Reinzoomen“). - scale_x_continuous(limits = ...) / scale_y_continuous(limits = ...) oder xlim()/ylim() → entfernt Werte ausserhalb (kann z. B. Ausreisser verschwinden lassen).
5) Aufteilen in mehrere kleine Grafiken: facet_* - facet_wrap(~ Shift) → eine Grafik pro Ausprägung (z. B. pro Schicht) - facet_grid(MachineType ~ Shift) → Matrix aus Teilgrafiken
Facets sind zentral für die EDA, weil sie Vergleiche sehr leicht machen.
Merksatz zum Lesen von ggplot-Code:
> ggplot(...) sagt worum es geht (Daten + Rollen).
> geom_*() sagt wie es aussieht (Darstellung).
> facet_*(), coord_*(), scale_*(), theme_*(), labs() machen es vergleichbar und lesbar.
Jetzt sind unsere Daten parat für die erste Visualisierung.
Visualisierungen I - Kategoriale Variablen mit Barplots (Stäbchendiagramme)
Bevor wir die Zusammenhänge zwischen numerischen Variablen analysieren (z. B. CycleTime vs. Load), müssen wir zuerst verstehen, wie unsere Daten “zusammengesetzt” sind. Ein grosser Teil unseres Datensatzes besteht aus kategorialen Variablen wie Shift, MachineType oder MachineID. Diese Variablen beschreiben keine Messwerte auf einer Skala, sondern Gruppen bzw. Kategorien. Wenn wir später Aussagen über die numerischen Merkmale von Gruppen oder Kategorien treffen wollen, müssen wir brücksichtigen, ob sie angemessen im Datensatz repräsentiert sind. Haben wir z.B. kaum Daten für eine Frühschicht, dafür viele Daten über die Nachtschicht, werden wir kaum zuverlässige Einsichten gewinnen.
Zweite Forschungsfrage Wie häufig kommt jede Kategorie vor? Sind alle Gruppen ausreichend vertreten – oder dominiert eine einzelne Kategorie?
Warum ist das wichtig?
Wenn z.B.70% aller Werkstücke in der Morning-Schicht produziert wurden, dann prägt diese Schicht automatisch die Verteilung von CycleTime. Ebenso können scheinbare Effekte entstehen, wenn ein Maschinentyp viel häufiger vorkommt als der andere. Bevor wir also Gruppen vergleichen (z. B. Boxplots pro Schicht) oder Zusammenhänge interpretieren, prüfen wir zuerst die Häufigkeiten der Kategorien.
Genau dafür verwenden wir Balkendiagramme (Barplots), welche wir uns als erstes ansehen.
TippBarplots in der EDA: Kategorien schnell verstehen
Wofür?
Balkendiagramme sind das Standardwerkzeug für kategoriale Variablen: sie zeigen, wie viele Beobachtungen in jeder Kategorie vorkommen.
Zwei typische Varianten - Normaler Barplot: Häufigkeiten pro Kategorie (z. B. wie viele Werkstücke pro Schicht?) - Gruppierter Barplot: Vergleich innerhalb einer Kategorie (z. B. Maschinentyp A vs. B je Schicht)
Zuerst vergleichen wir die verschiedenen Schichten
Code
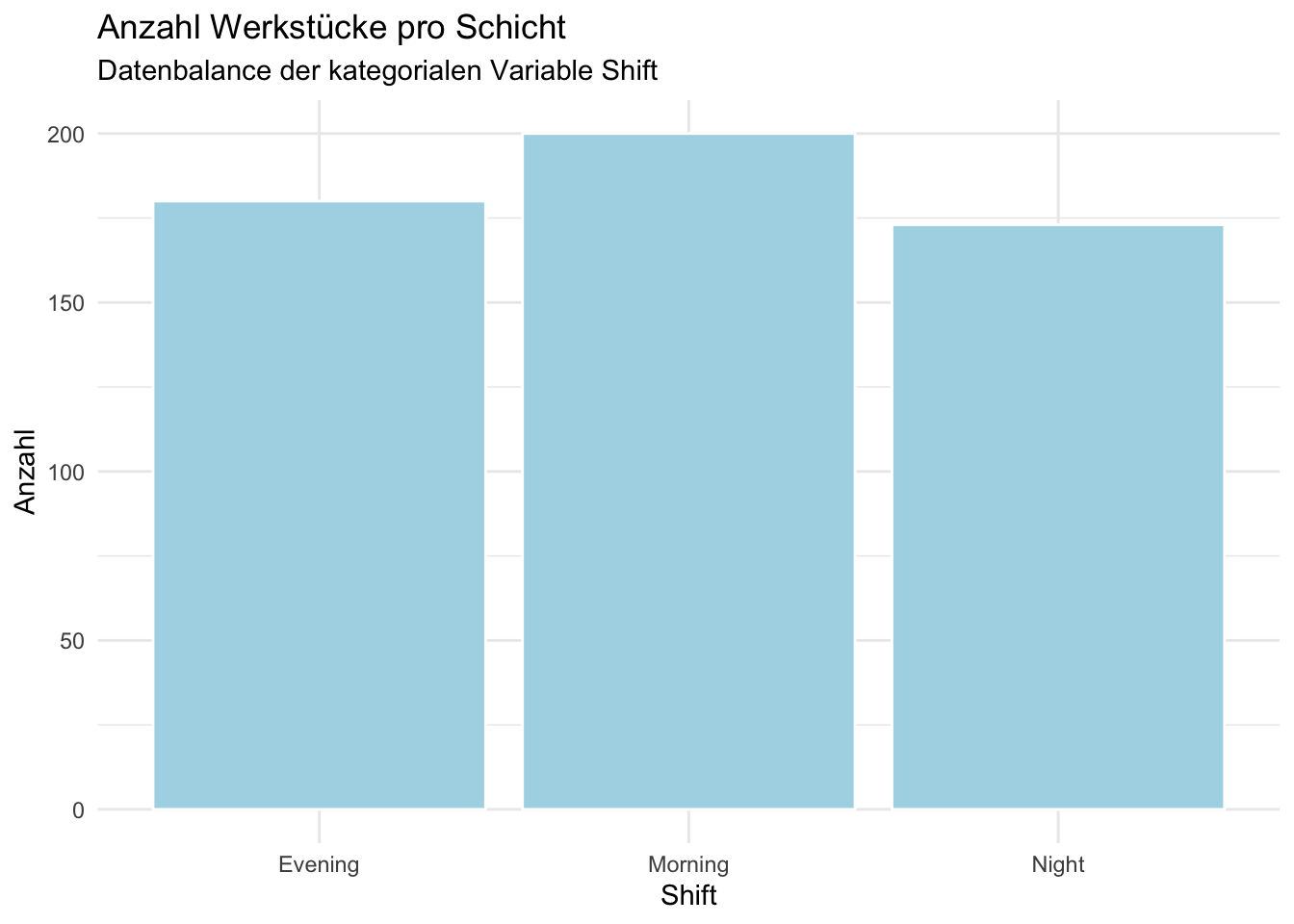
ggplot(eda_data, aes(x = Shift)) +geom_bar(fill ="lightblue", color ="white") +labs(title ="Anzahl Werkstücke pro Schicht",subtitle ="Datenbalance der kategorialen Variable Shift",x ="Shift",y ="Anzahl" ) +theme_minimal()
Wir sehen Unterschiede, aber sie sind nicht sehr gross. Nur die Morning Schicht stellt ca. 15% mehr Werkstücke her als die beiden anderen \(\Rightarrow\) keine Auffälligkeiten.
Neben den Schichten gibt es noch verschiedene Maschinentypen, die vielleicht unterschiedliche Anzahl Werkstücke produzieren. Dies können wir durch einen Gruppenbarplot darstellen, der die gerade gezeigten Blöcke ergänzt.
Code
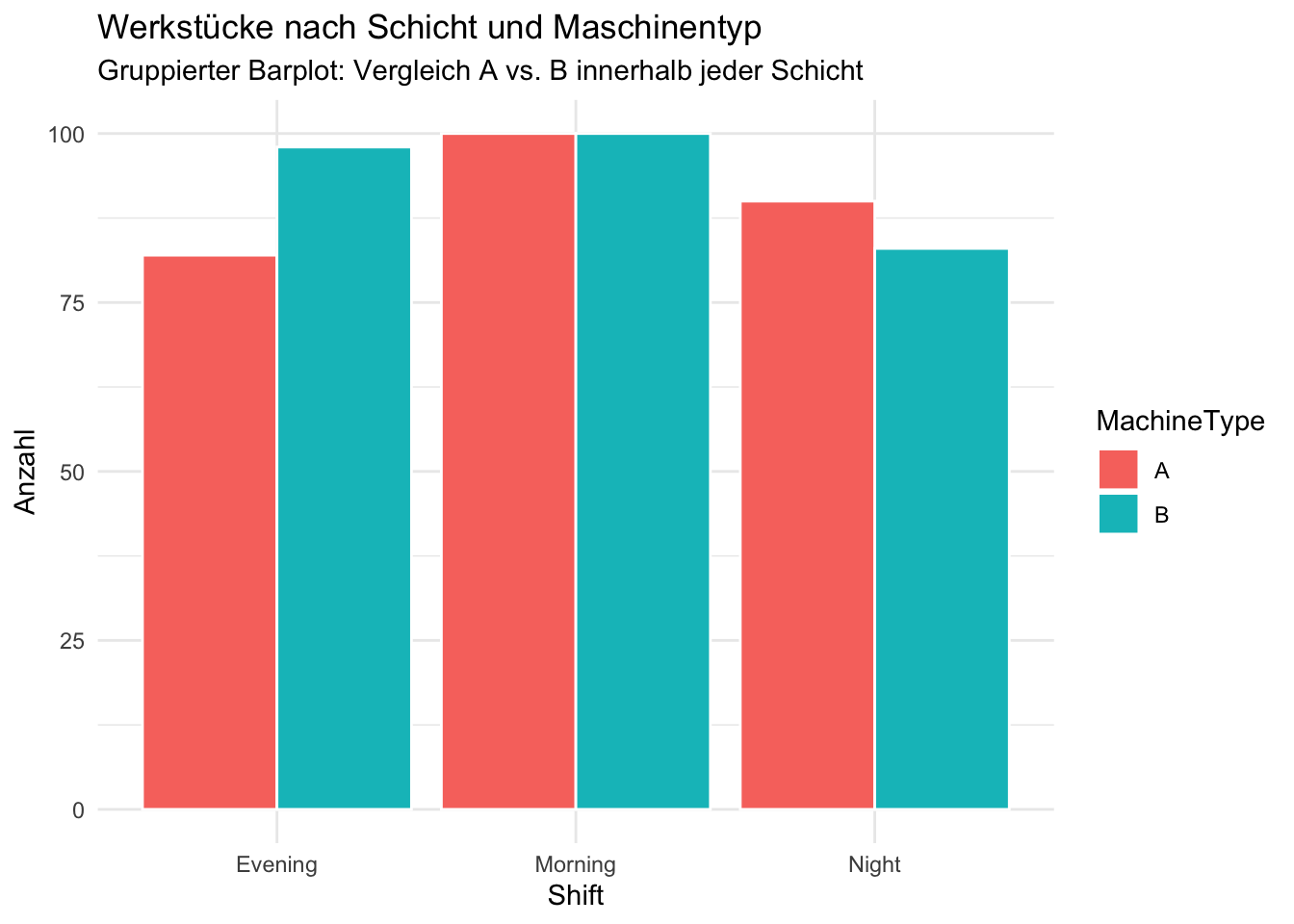
ggplot(eda_data, aes(x = Shift, fill = MachineType)) +geom_bar(position ="dodge", color ="white") +labs(title ="Werkstücke nach Schicht und Maschinentyp",subtitle ="Gruppierter Barplot: Vergleich A vs. B innerhalb jeder Schicht",x ="Shift",y ="Anzahl",fill ="MachineType" ) +theme_minimal()
Es gibt Unterschiede je nach Maschinentyp, aber Evening und Night produzieren für Typ A einem mehr, einmal weniger Werkstücke. In der Morning Schicht unterscheiden sie sich gar nicht. Wir sehen keine Auffälligkeit, die gross genug ist um von unausgewogenen Daten sprechen zu können.
Fazit Visualisierungen I:
Die Gruppen sind gut vergleichbar: Jede Schicht enthält genügend Beobachtungen, und die Maschinentypen A/B sind innerhalb der Schichten ähnlich häufig.
Damit sind Vergleiche wie Boxplots oder Scatterplots nach Shift und MachineType sinnvoll, ohne dass ein offensichtliches Ungleichgewicht die Ergebnisse verzerrt.
Visualisierungen II - Histogramme und Boxplots
Nachdem wir uns vergewissert haben, dass wir in allen Kategorien genügend Messwerte besitzen, fragen wir jetzt:
Dritte Forschungsfrage: Wie treten die Produktionszeiten hinsichtlich ihrer Häufigkeit auf?
Dazu fertigen wir ein sog.Histogramm an.
Code
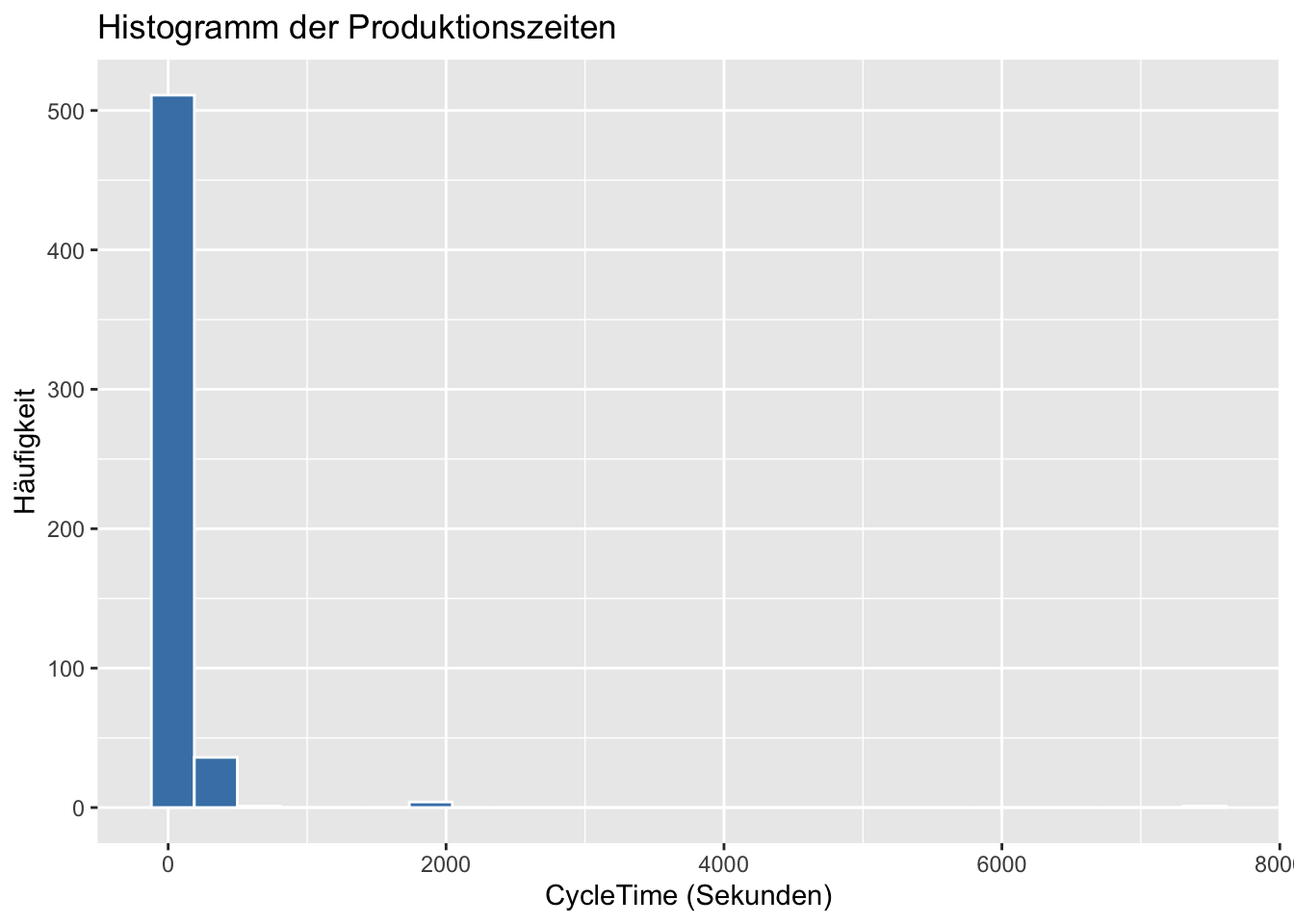
ggplot(eda_data, aes(x = CycleTime)) +geom_histogram(bins =25, fill ="steelblue", color ="white") +labs(title ="Histogramm der Produktionszeiten",x ="CycleTime (Sekunden)",y ="Häufigkeit" )
Dazu können wir uns vorstellen, dass wir die Messwerte der Grösse nach anordnen und sie dann in vorgegebene Grössenintervallen zuordnen. Jedes Intervall bekommt einen Balken und die Höhe des Balkens entspricht der Anzahl Messwerte in seinem Intervall. Wir sehen, dass die grosse Mehrheit der Produktionszeiten auf nur zwei Balken um 0-100 Sekunden verteilt sind und einige wenige grosse Ausreisser existieren. Schauen wir uns den Code an (die Details der Syntax sehen wir uns nach der Visualisierung genauer an), so finden wir mit bins die Anzahl der Intervalle oder “Eimer” in die die Daten aufgeteilt werden. Vielleicht ist unsere Darstellung zu grob, d.h. es gibt noch interessante Informationen innerhalb der bins. Ausserdem wollen wir den Einfluss der Ausreisser mit sehr geringer Häufigkeit für einen Moment ausblenden und beschränken die Werte für CycleTime auf 500.
HinweisAufgabe: Abhängigkeit des Histogramms von der Anzahl der Bins
Aufgabe: Varrieren Sie mit der Anzahl bins und beobachten Sie, wie sich das Histogramm verändert.
Überlegen Sie insbesondere:
Was passiert, wenn Sie sehr wenige Bins wählen?
Was passiert, wenn Sie sehr viele Bins wählen?
Welche Wahl hilft, die Form der Verteilung (z. B. Schiefe, Ausreisser, mehrere Peaks) sinnvoll zu erkennen?
Was beobachten Sie? Wie beeinflusst die Anzahl bins die sichtbare Informationen des Histogramms?
Code
library(patchwork)library(tidyverse)eda_data_500 <- eda_data %>%filter(CycleTime <500)# 1) Plot: kleinste Anzahl binsp1 <-ggplot(eda_data_500, aes(x = CycleTime)) +geom_histogram(bins = ___, fill ="steelblue", color ="white") +labs(title ="bins = ___",subtitle ="nach Faustregel",x ="CycleTime",y ="Häufigkeit" )# 2) Plot: mehr binsp2 <-ggplot(eda_data_500, aes(x = CycleTime)) +geom_histogram(bins = ___, fill ="indianred", color ="white") +labs(title ="bins = ___",x ="CycleTime",y ="Häufigkeit" )# 3) Plot: sehr viele binsp3 <-ggplot(eda_data_500, aes(x = CycleTime)) +geom_histogram(bins = ___, fill ="indianred", color ="darkgreen") +labs(title ="bins = ___",x ="CycleTime",y ="Häufigkeit" )# Alle drei Plots nebeneinander anzeigenp1 + p2 + p3
Musterlösung anzeigen
Code
library(patchwork)eda_data_500 <- eda_data %>%filter(CycleTime<500)# 1. Plot: bins = 24 nach Faustregelp1 <-ggplot(eda_data_500, aes(x = CycleTime)) +geom_histogram(bins =24, fill ="steelblue", color ="white") +labs(title ="bins = 24",subtitle ="nach Faustregel",x ="CycleTime",y ="Häufigkeit" )# 2. Plot: Filtern mit xlim (Daten > 1000 werden gelöscht)p2 <-ggplot(eda_data_500, aes(x = CycleTime)) +geom_histogram(bins =50, fill ="indianred", color ="white") +labs(title ="bins = 50",x ="CycleTime",y ="Häufigkeit" )# 3. Plot: `bins`= 200p3 <-ggplot(eda_data_500, aes(x = CycleTime)) +geom_histogram(bins =100, fill ="indianred", color ="darkgreen") +labs(title ="bins = 100",x ="CycleTime",y ="Häufigkeit" )# Beide nebeneinander anzeigenp1 + p2 + p3
Diskussion und Interpretation:
Die Anzahl bins bestimmt, wie grob oder fein das Histogramm die Verteilung darstellt – die Daten bleiben gleich, aber die sichtbare Struktur ändert sich.
Sehr wenige Bins: Das Histogramm wirkt glatt und grob. Wichtige Details (z. B. kleine Peaks oder Knicke) können untergehen.
Mittlere Bin-Anzahl (z. B. 24–50): Guter Kompromiss: Form der Verteilung (Schiefe, Ausreisser, Häufungen) ist meist gut erkennbar und noch gut lesbar.
Sehr viele Bins: Das Histogramm wird zackig. Man sieht viel “Struktur”, aber ein Teil davon ist oft Zufallsrauschen → Gefahr der Überinterpretation.
Fazit: Mit bins spielen hilft zu prüfen, ob Muster stabil sind oder nur durch die Darstellung entstehen.
Histogramme und ihre Eigenschaften können wir so zusammenfassen:
TippHistogramm: Verteilungen sehen
Wofür?
- Form der Verteilung erkennen: schief? mehrere Gipfel? lange Schwänze? - Grobe Häufigkeiten/Cluster sichtbar machen
Wichtigste Eigenschaften - Zeigt Häufigkeiten in Klassen (Bins).
- Ergebnis hängt von bins / binwidth ab (zu grob/zu fein kann täuschen). Als Fausformel zur sinnvollen Anzahl bins kann man sich in der Praxis an die Fausformel halten: \[
`bins`=\sqrt{n}; \quad \text{n=Anzahl Messwerte}
\] - Ausreisser sind nicht als Punkte markiert, sondern „stecken“ in seltenen Bins am Rand.
Wenn man in der Praxis viele Klassen besitzt, die nur eine sehr kleine Anzahl von Datenpunkten enthalten, kann es sinnvoll sein statt bins gleicher Intervalllänge besser unterschiedliche Länge zu benutzen. Dabei muss man aber vorsichtig sein, den optischen Eindruck nicht zu verfälschen.
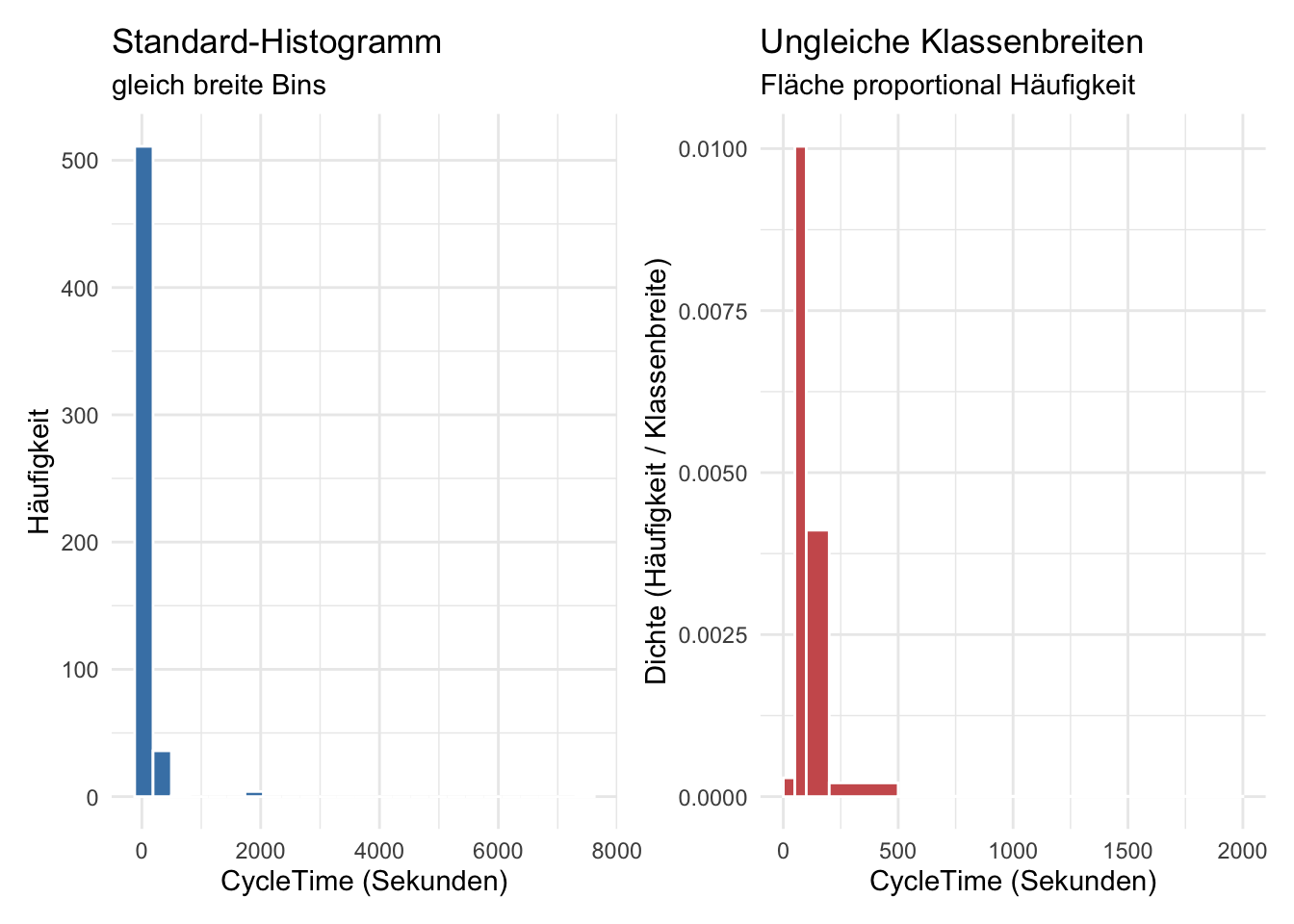
WarnungHistogramme mit ungleich breiten Klassen: Höhe ≠ Häufigkeit!
Normalerweise sind Histogramm-Klassen (Bins) gleich breit. Dann gilt: Höhe des Balkens ∝ Häufigkeit.
Es gibt aber auch den Fall, dass es sinnvoll ist Klassenbreiten ungleich zu wählen.
Warum überhaupt ungleiche Klassenbreiten?
Auf den ersten Blick wirkt es widersprüchlich: Ungleiche Klassenbreiten machen das Histogramm komplizierter, weil die y-Achse dann eine Dichte statt einer einfachen Häufigkeit zeigt. Trotzdem sind ungleiche Klassenbreiten in der Praxis manchmal genau das Richtige.
Wann ist das sinnvoll?
Sehr schiefe Verteilungen / lange tails:
Wenn die Daten einen dichten Bereich (z. B. 0–200 s) und gleichzeitig wenige extreme Ausreisser (z. B. bis 2000 s) haben, dann sind gleich breite Bins oft ein schlechter Kompromiss:
Entweder sind die Bins im dichten Bereich zu grob oder der tail dominiert die Achse.
Mehr Auflösung dort, wo die Daten „passieren“:
In Bereichen mit vielen Beobachtungen wählt man schmale Bins, um Struktur zu sehen.
Im Tail wählt man breitere Bins, um seltene Werte kompakter zu gruppieren.
Interpretation bleibt korrekt über Flächen:
Auch wenn die y-Achse eine Dichte zeigt, bleibt die wichtigste Aussage erhalten: Die Fläche eines Balkens entspricht der Häufigkeit.
Damit kann man trotz unterschiedlicher Breiten fair vergleichen.
Mathematischer Hintergrund
Würde man einfach die Bins breiter machen, hätte diese „mehr Fläche“ und wirkt optisch häufiger falsch.
Regel: Bei ungleichen Klassen muss die Fläche eines Balkens die Häufigkeit repräsentieren.
Dazu verwendet man die Häufigkeitsdichte (Density):
\[
\text{Häufigkeitsdichte im Bin } j
\;=\;
\frac{\text{Häufigkeit im Bin } j}{\text{Klassenbreite } w_j}.
\]
Der optische Eindruck ist zwar ähnlich, aber mit ungleichen Bins wird hervorgehoben, dass die sehr viele Messwerte in einem schmalen Intervall konzentriert sind (höchste Dichte)
Der visuelle Eindruck, wie die Datenwerte verteilt sind liefert uns schon viele wichtige Informationen. In der Praxis wollen wir aber häufig auch quantitative Kennwerte, die kompelementär die visuellen Informationen ergänzen. Sie nennen wir in der Statistik und im Data Science Metriken oder Kennzahlen. In der nächsten Box sehen wir eine Übersicht über die wichtigsten für unsere EDA.
HinweisDeskriptive Kennzahlen: Zahlen zum Histogramm
Ein Histogramm zeigt die Verteilung visuell – die folgenden Kennzahlen fassen sie als Zahlen zusammen.
Lage (typischer Wert)
Arithmetisches Mittel\[
\bar{x}=\frac{1}{n}\sum_{i=1}^n x_i
\]Anschaulich: „Durchschnitt“. Jede Beobachtung zählt gleich stark – dadurch reagiert \(\bar{x}\) empfindlich auf sehr grosse/kleine Werte (Ausreisser).
Median\[
\tilde{x}=
\begin{cases}
x_{(\frac{n+1}{2})}, & n \text{ ungerade}\\[4pt]
\frac{1}{2}\left(x_{(\frac{n}{2})}+x_{(\frac{n}{2}+1)}\right), & n \text{ gerade}
\end{cases}
\] wobei \(x_{(1)}\le \dots \le x_{(n)}\) die sortierten Werte sind. Anschaulich: „Die Mitte“: 50% der Werte liegen darunter, 50% darüber. Robust gegenüber Ausreissern.
Modus
Der Modus ist der Wert (oder die Klasse), der am häufigsten vorkommt. Anschaulich: „Der häufigste Wert“ bzw. die höchste Säule im Histogramm.
Bei kategorialen Daten ist der Modus oft die wichtigste Lagekennzahl.
Bei metrischen Daten wird der Modus im Histogramm meist als häufigstes Intervall sichtbar und hängt daher von der Wahl der bins ab.
Eine Verteilung kann mehrere Modi haben (bimodal / multimodal), z. B. wenn zwei Gruppen gemischt sind.
Streuung (wie stark variieren die Werte?)
Varianz / Standardabweichung\[
s^2=\frac{1}{n-1}\sum_{i=1}^n (x_i-\bar{x})^2,
\qquad
s=\sqrt{s^2}
\]Anschaulich: Typische Abweichung vom Mittelwert. Weil quadriert wird, wirken Ausreisser stark mit.
Spannweite\[
R=\max(x)-\min(x)
\]Anschaulich: Gesamte Breite der Daten – sehr empfindlich gegenüber Ausreissern (ein einziger Extremwert reicht).
Schiefe (Form der Verteilung – grober Schnelltest)
Mittelwert vs. Median
rechtsschief (langer rechtes Ende der Verteilung (tail)): \(\bar{x}>\tilde{x}\)
linksschief (langer linker Ende der Verteilung (tail)): \(\bar{x}<\tilde{x}\)
Anschaulich: Extreme grosse Werte ziehen den Mittelwert nach rechts (oben); der Median bleibt „in der Mitte“. Man kann deshalb sagen, der Median ist robuster gegen Ausreisser als der arithm. Mittelwert.
Bestimmen wir jetzt diese Lage- und Streumasse/-kennwerte unserer Daten:
Mean Median SD IQR Min Max
1 138.2157 98.93118 350.715 36.32979 33.73986 7459.491
Was lernen wir aus diesen Metriken über die Verteilung der Messwerte?
Der Wert des Medians, \(\tilde{x}\), liegt viel tiefer als der arithm. Mittelwert/mean, \(\bar{x}\). Dies sagt uns, dass die Verteilung rechtsschief ist, d.h. sie besitzt mehr Datenwerte unterhalb von \(\bar{x}\), als oberhalb \(\rightarrow\) Verteilung ist nicht symmetrisch ; Der Grund ist, das wir hier einige Ausreisser haben mit hohen Messwerten, die den Wert von \(\bar{x}\) nach oben ziehen. Der Median ist hier viel robuster und weitgehend unberührt von den Ausreissern.
Max zeigt uns, dass es sehr grosse Ausreisser gibt, während Min nur knapp unter \(\bar{x}\) liegt.
Im Histogramm mit der höheren Anzahl bins können wir nur sehr grob schätzen, wo \(\bar{x}\) und \(\tilde{x}\) liegen. Die mathematischen Definition geben uns quantitative Werte, dies auch erlauben Verteilungen nach ihren Metriken zu vergleichen.
HinweisVerständnisfrage: Arithmetischer Mittelwert und der höchste Histogrammbalken
Frage:
Angenommen, wir wählen „geeignete“ Bins. Ist der arithmetische Mittelwert \(\bar{x}\) dann identisch mit dem x-Wert des höchsten Histogrammbalkens?
Antwort anzeigen
Nein. Der arithmetische Mittelwert \(\bar{x}\) ist ein Lageparameter und berücksichtigt alle Werte:
\[
\bar{x}=\frac{1}{n}\sum_{i=1}^n x_i.
\]
Der höchste Histogrammbalken entspricht dagegen dem Bereich (Bins), in dem am meisten Beobachtungen liegen. Das ist (je nach Darstellung) näher am Modus (häufigster Wertbereich) als am Mittelwert.
\(\bar{x}\) und „höchster Balken“ fallen nur in Spezialfällen ungefähr zusammen, z. B. bei einer symmetrischen, unimodalen Verteilung ohne starke Ausreisser – und selbst dann hängt die Position des höchsten Balkens stark von der Binbreite und den Bin-Grenzen ab.
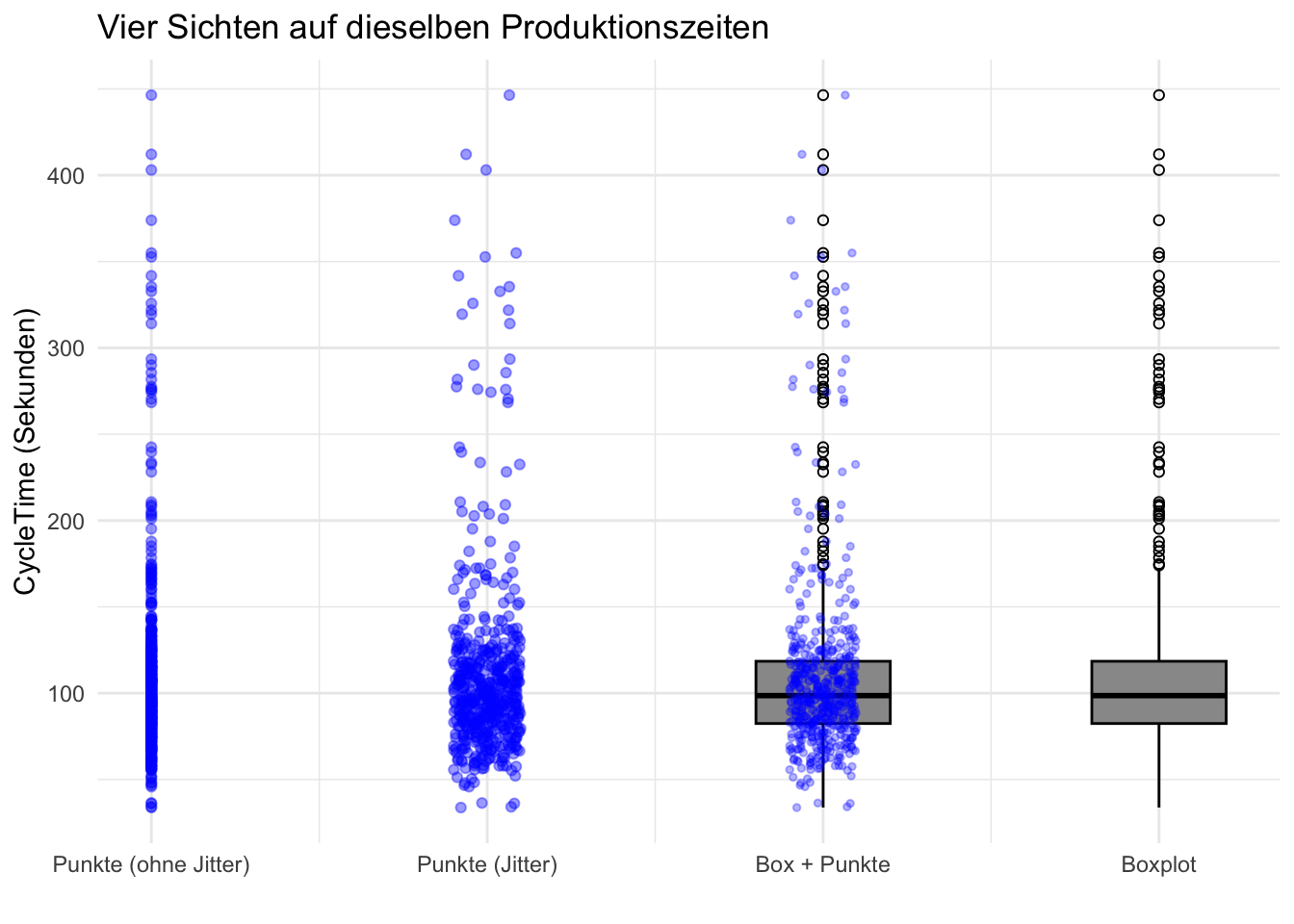
Das Histogramm hat uns schon wertvolle Hinweise über CycleTimegeliefert, jetzt möchte wir aber die Häufung der Messwerte aus einer anderen Perspektive betrachten. Deshalb plotten wir alle Punkte vertikal übereinander.
Code
ggplot(eda_data, aes(x =0, y = CycleTime)) +geom_point(alpha =0.4, color ="blue") +labs(title ="Produktionszeiten (alle Punkte übereinander)",x ="",y ="CycleTime (Sekunden)" ) +theme_minimal() +theme(axis.text.x =element_blank(),axis.ticks.x =element_blank() )
Wir sehen, dass die wenigen Ausreisser die Darstellung dominieren und wir so kaum eine Information erhalten über die grosse Mehrheit der Datenpunkte. Wir limitieren deshalb die Werte für CycleTime wieder auf 500 Sekunden. Um die Verteilung der Datenpunkte besser zu sehen, führen wir eine statistische Abweichung in den Plot ein (sog. jitter).
Code
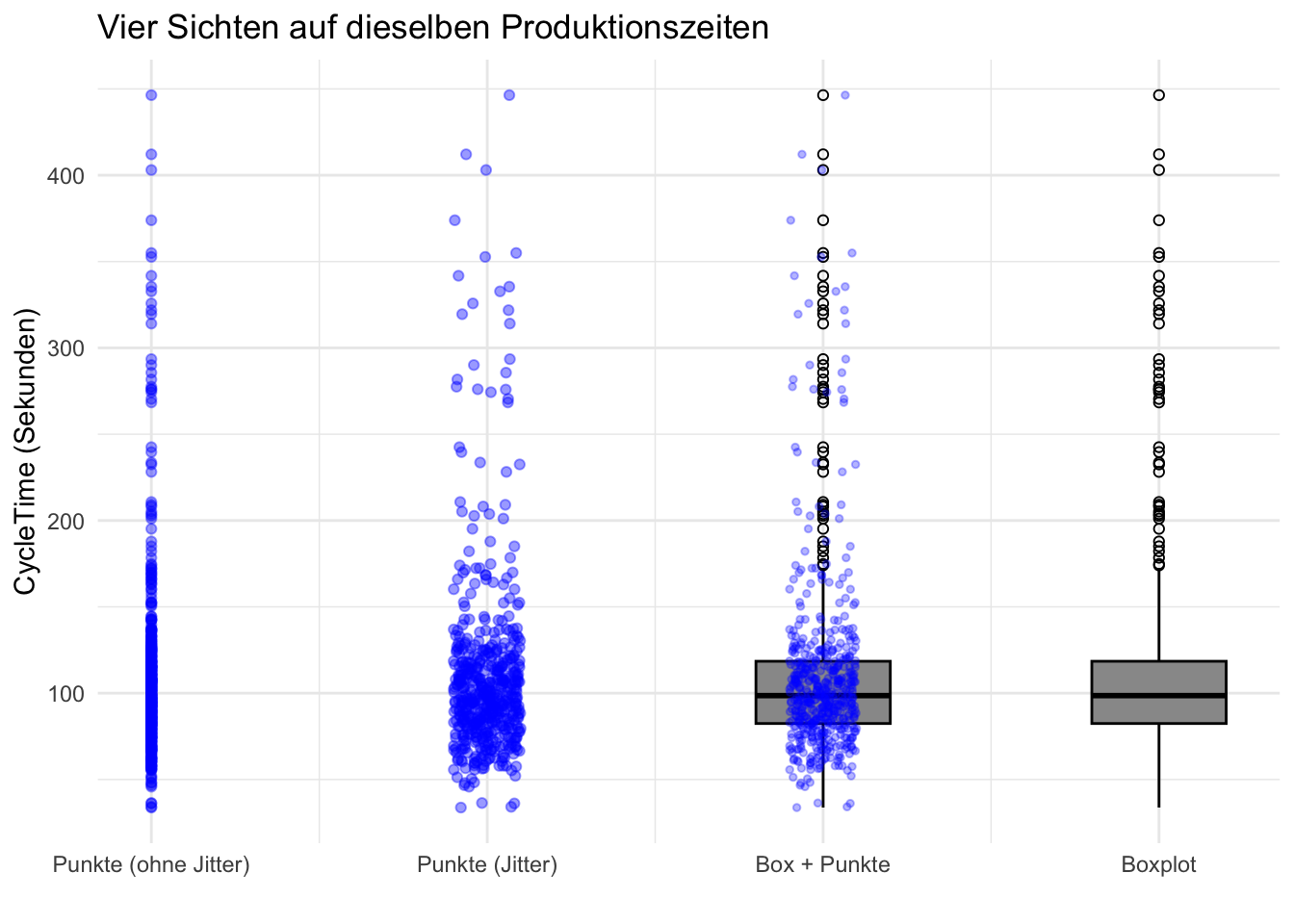
set.seed(42) # für reproduzierbare Jitterwerte# Ein Jitter-Vektor um x = 1, den wir mehrfach verwendenj <-jitter(rep(1, nrow(eda_data_500)), amount =0.1)eda_data_kurz <- eda_data_500 %>%mutate(x_col =0, # Punkte ohne Jitterx_jitter = j, # Punkte mit Jitter (Zentrum ~1)x_boxjit = j +1# gleiche Punkte, nach rechts verschoben (Zentrum ~2) )ggplot(eda_data_kurz, aes(y = CycleTime)) +# 1) LINKS: Punkte alle exakt übereinander (kein Jitter)geom_point(aes(x = x_col), alpha =0.4, color="blue") +# 2) 2. Spalte: nur Jittergeom_point(aes(x = x_jitter),color="blue", alpha =0.4) +# 3) 3. Spalte: Boxplot + die gleiche Punktwolkegeom_boxplot(aes(x =2),width =0.4,fill ="grey60",color ="black",outlier.shape =1 ) +geom_point(aes(x = x_boxjit),color="blue", alpha =0.3, size =1) +# 4) 4. Spalte: nur Boxplotgeom_boxplot(aes(x =3),width =0.4,fill ="grey60",color ="black",outlier.shape =1 ) +scale_x_continuous(breaks =c(0, 1, 2, 3),labels =c("Punkte (ohne Jitter)","Punkte (Jitter)","Box + Punkte","Boxplot" ) ) +labs(title ="Vier Sichten auf dieselben Produktionszeiten",x ="",y ="CycleTime (Sekunden)" ) +theme_minimal()
Ohne Jitter sehen wir nur einen Strich aus Punkten.Der Jitter gibt uns einen Einblick in die Dichte, mit der die Messwerte auftreten. Mit der grauen Box führen wir jetzt eine kompakte Visualisierung wichtiger Eigenschaften der Messwerte (man sagt auch univariate Daten) ein: Den Boxplot
TippBoxplot – wofür und was zeigt er?
Wofür? Kompakter Überblick über Lage und Streuung; ideal zum Vergleich von Gruppen.
Wichtigste Eigenschaften
Box = Q1 bis Q3 (IQR), Linie in der Box = Median = \(\tilde{x}\)
Whisker bis zum letzten Wert innerhalb 1.5·IQR
Werte ausserhalb sind Ausreisser und werden standardmässig als Kringel oder Punkte geplottet
Q steht für Quartile, von lat. quartus, der Vierte, hier “ein Viertel” (wie in Stadtviertel). Wenn ich 100 Messwerte der Grösse nach anordne und durchnummeriere, dann wäre die 1.Quartile der Wert des 25.Messwerts, die 2.Quartile (sog. Median) der des 50. und die 3.Quartile der 75.Messwert.
Q1: 1.Quartile
Q3: 3.Quartile
IQR: Interquartile distance
Die Quartilen können wir natürlich auch als Kennwerte direkt aus den Daten mit R berechnen:
Q1 Median Q3 IQR Mean
1 82.41654 98.58036 118.4773 36.0608 111.1703
WarnungWarnung
Vorsicht, wir haben den ursprünglichen Datensatz gefilter! Deshalb sind die Quartilwerte und das IQR jetzt verschieden vom vollständigen Datensatz!
Die vertikalen Striche, Whisker haben die Länge von 1.5*Boxlänge(=IQR) und dient dazu pragmatisch die Ausreisser zu definieren, die jenseits dieser Striche liegen und als Kringel eingezeichnet werden.Wir sehen, dass schon bei Werten über ca.170 die Ausreisser nach dieser Definition beginnen. Wir erinnern uns an die Aussage der Leiterin der Qualitätssicherung, dass Werte unter 200 Sekunden in Ordnung sind und dass die grosse Mehrheit diese Bedingung erfüllen. Dies sehen wir mit einem Blick auf den Boxplot. Wir müssen uns also auf die Ausreisser konzentrieren. Was aber ist charakteristisch für diese Ausreisser? Treten Sie nur bei hoher Last oder nur in einer bestimmten Produktionschicht auf?
Wir entscheiden uns für die Abhängigkeit der Produktionszeit von der Last.
Vierte Forschungsfrage: Tritt für hohe Produktionszeit auch ein hoher Wert der Last auf?
Visualisierungen III - Streudiagramme - side-by-side Boxplots
Um die Abhängigkeit der beiden Variablen sichtbar zu machen, plotten wir sie in ein sog. Streudiagramm (scatter plot)
Code
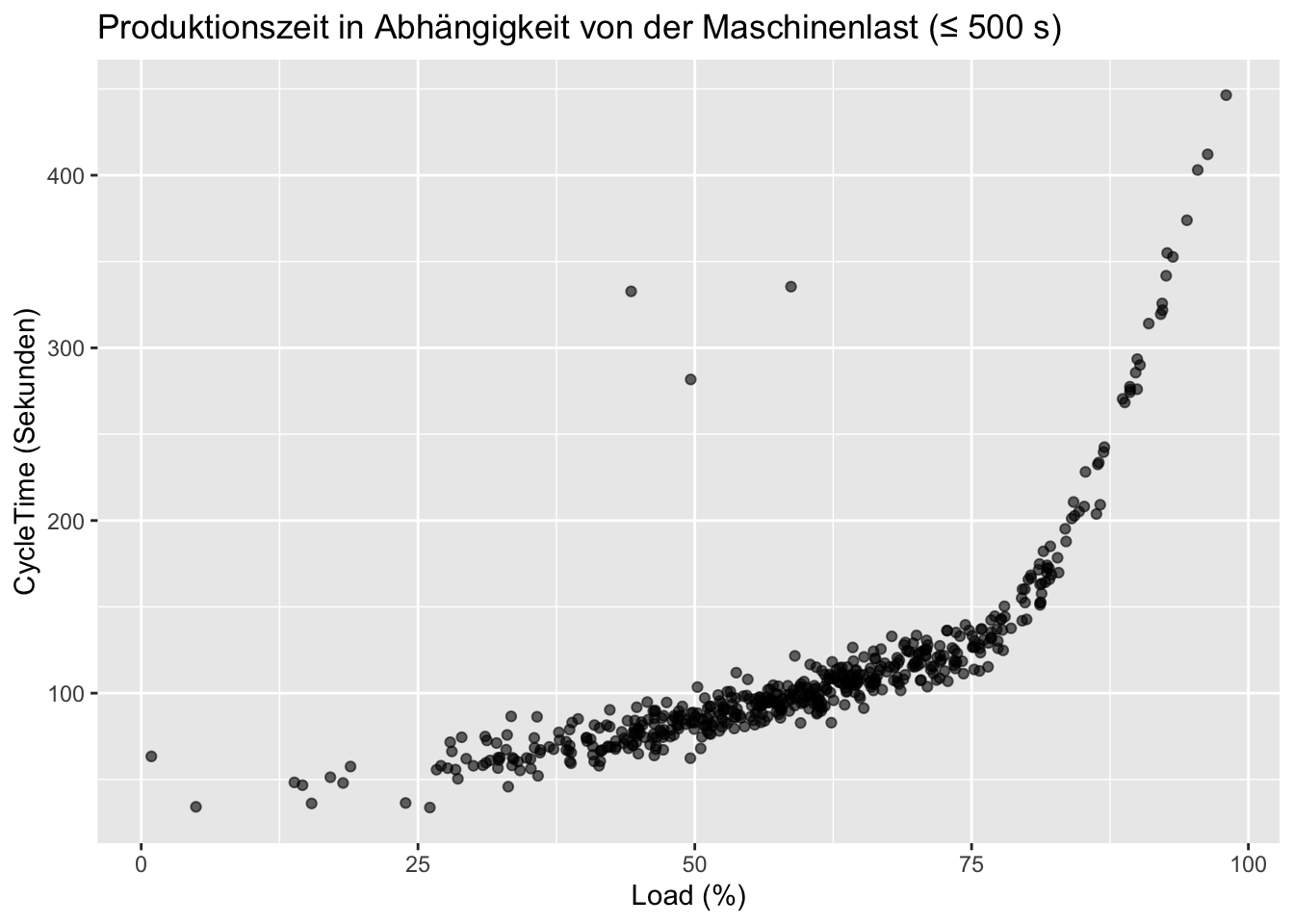
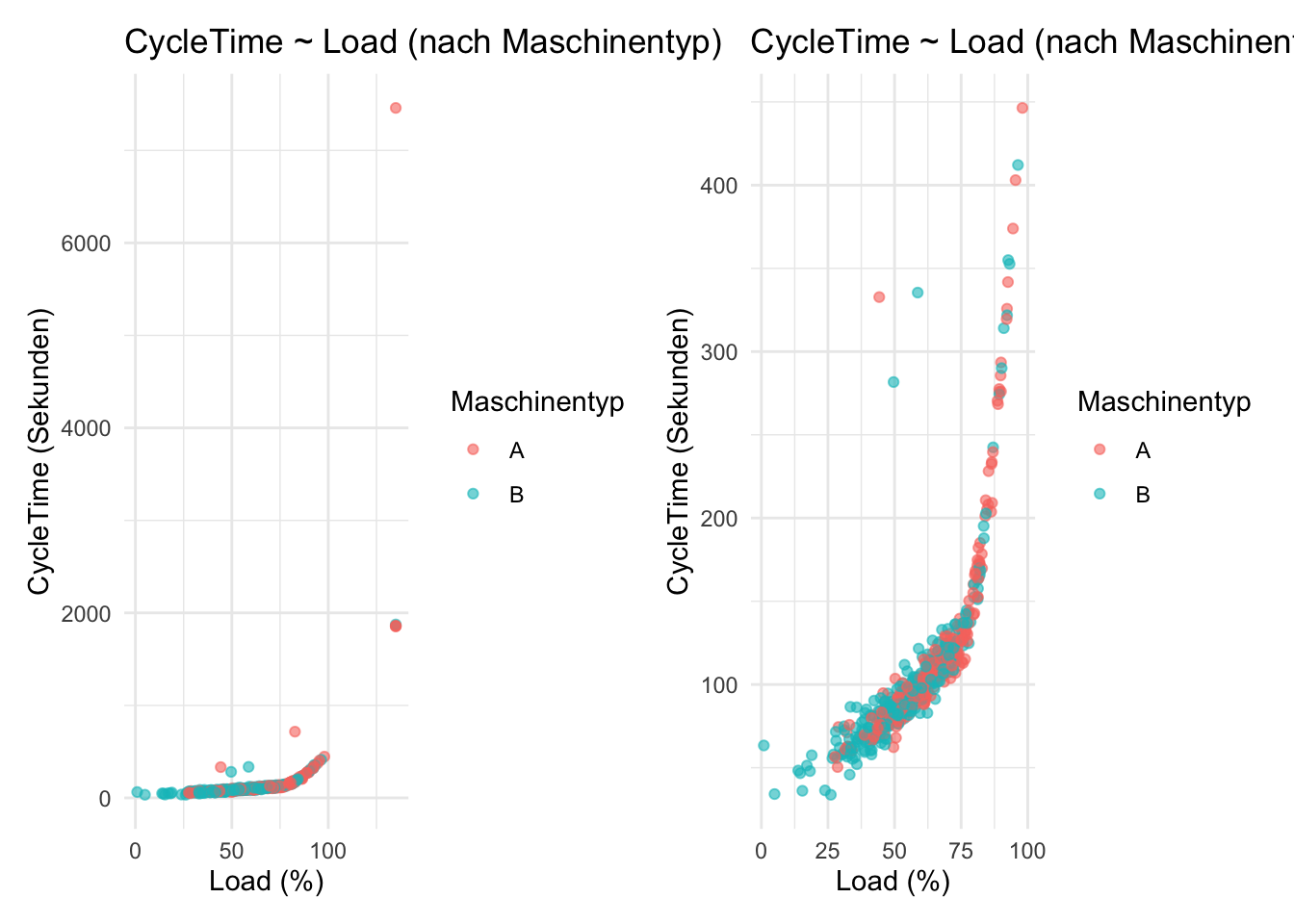
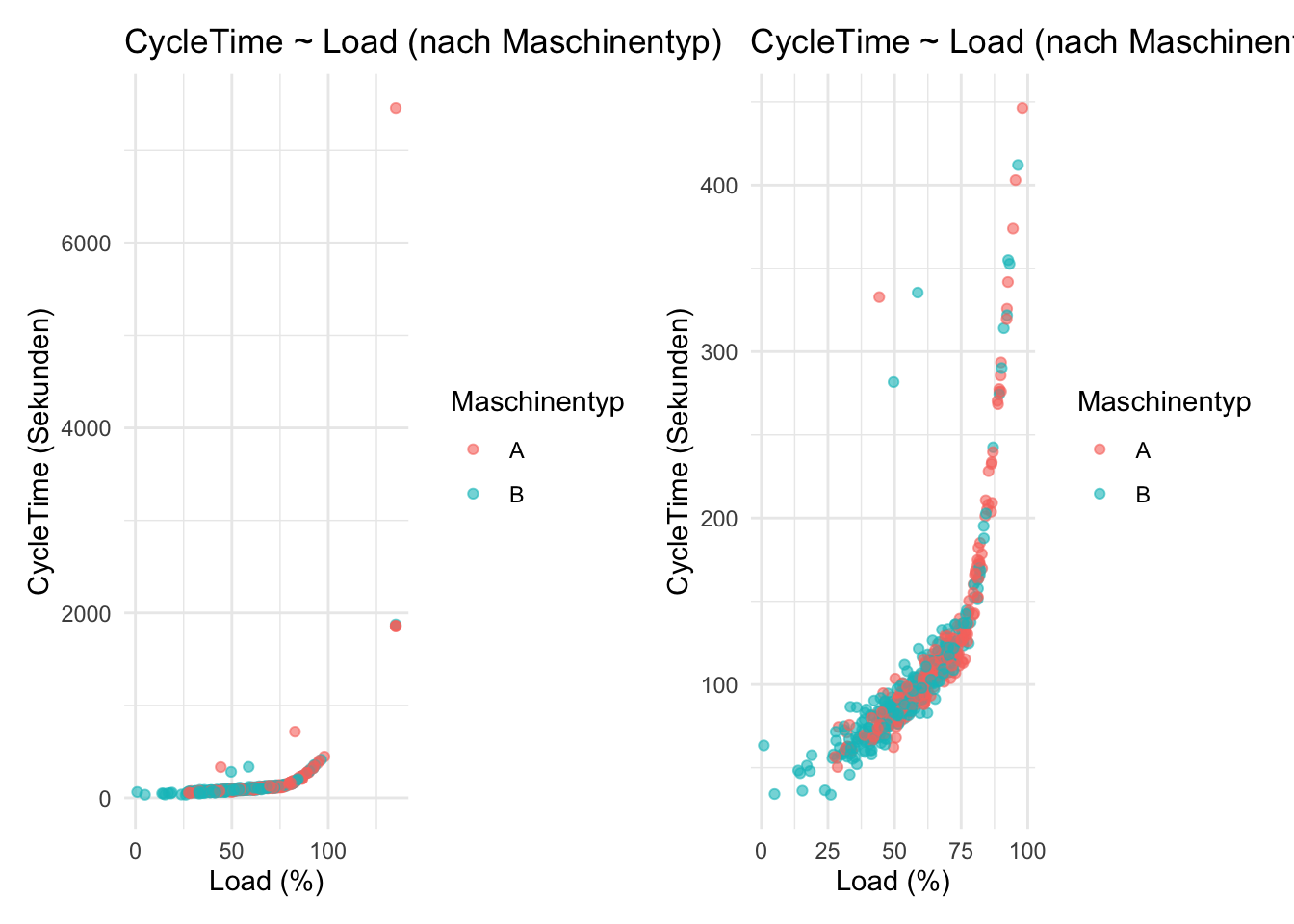
ggplot(eda_data, aes(x = Load, y = CycleTime)) +geom_point(alpha =0.6) +labs(title ="Produktionszeit in Abhängigkeit von der Maschinenlast",x ="Load (%)",y ="CycleTime (Sekunden)" )
Die Last (Load) nimmt qualitativ ab ca. 25% langsam zu und zeigt einen “Knick”, d.h. steileren Anstieg ab ca. 75%. Das wollen wir aber etwas genauer ansehen und plotten nochmals, aber nur bis zu Werten von 500 um den Einfluss der Aureisser zu begrenzen:
Code
ggplot(eda_data_500,aes(x = Load, y = CycleTime)) +geom_point(alpha =0.6) +labs(title ="Produktionszeit in Abhängigkeit von der Maschinenlast (≤ 500 s)",x ="Load (%)",y ="CycleTime (Sekunden)" )
Hier sehen wir jetzt den “Knick” ausgeprägter und stellen fest, dass ab ca. 80% Last der erlaubte Grenzwert von 200% überschritten wird. Nun wissen wir, dass der Lastanstieg zu höheren Produktionszeiten führt, aber nicht, ob auch andere Variablen Einfluss auf die Last haben. Besteht vielleicht ein Zusammenhang mit der (Betriebs)Temperatur der Maschine?
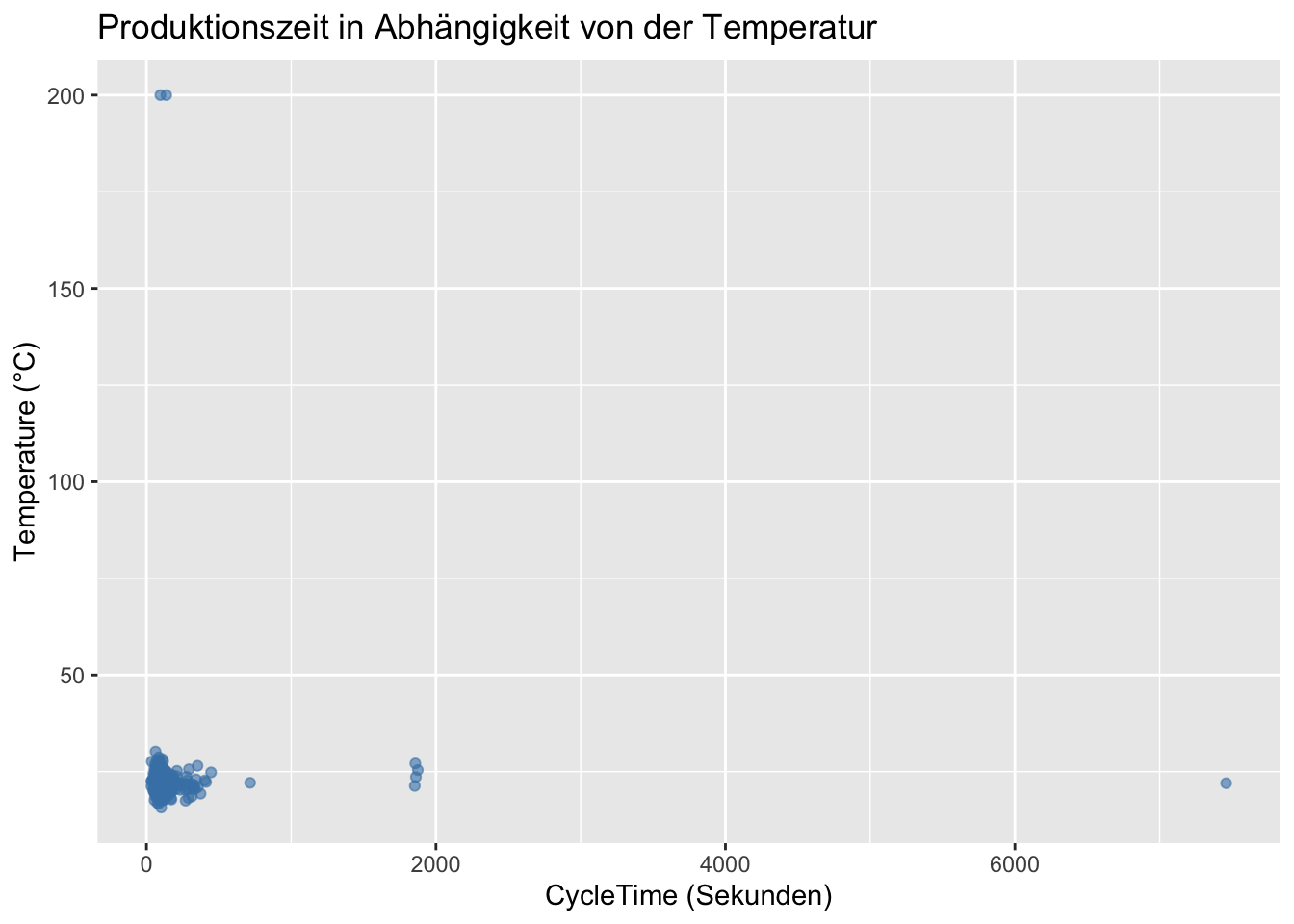
Fünfte Forschungsfrage: Sehen wir einen Zusammenhang zwischen CycleTime und temperature?
Code
ggplot(eda_data, aes(x = CycleTime, y = Temperature)) +geom_point(alpha =0.6, color ="steelblue") +labs(title ="Produktionszeit in Abhängigkeit von der Temperatur",y ="Temperature (°C)",x ="CycleTime (Sekunden)" )
Hier sehen wir Cluster von Datenpunkten, die aber kaum eine nennenswerte Erhöhung der Temperatur in Abhängigkeit von der Produktionszeit zeigen. Nur zwei Ausreisser bei 200°C sind sichtbar, dies müsste man genau ansehen, sind in der Anzahl aber so gering, dass wir für den Moment darauf verzichten.
Was lernen wir daraus? Wir sehen, dass die Temperatur kaum eine Abhängigkeit von der Last zeigt, von den beiden Ausreissern abgesehen. Man hätte eher erwartet, dass bei hoher Last eine erhöhte Arbeitstemperatur zeigt, was hier verneint werden kann. Kommen wir nochmals zum nichtlinearen Zusammenhang zwischen CycleTime und Load zurück. Zwei mögliche Abhängigkeiten haben wir noch nicht betrachtet.
Sechste und siebte Forschungsfrage:
- Hängen die Produktionszeiten von der Schicht ab? (anderes Personal, weniger Überwachung der Prozesse etc.) - Verhalten sich die Maschinentypen unterschiedlich
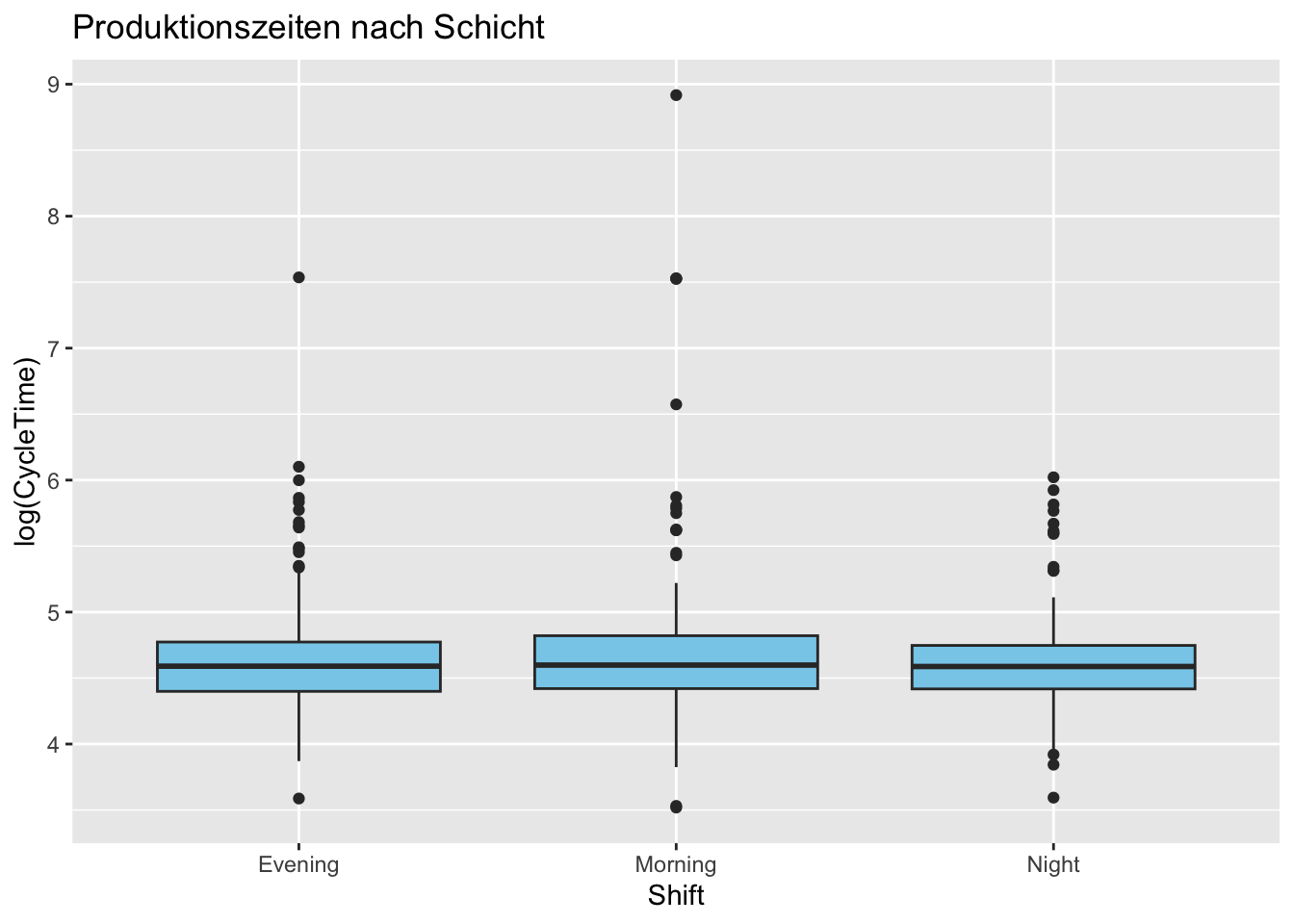
Beginnen wir mit der Schicht. Hierfür schauen wir uns die Boxplots aufgeteilt nach Schicht an mit logarithmierten Zeiten um die Dominanz der Ausreisser zu minimieren:
Code
ggplot(eda_data, aes(x = Shift, y =log(CycleTime))) +geom_boxplot(fill ="skyblue") +labs(title ="Produktionszeiten nach Schicht")
Das Logarithmieren ist generell eine Methode um entweder Nichtlinearitäten oder extreme Ausreisser in ihrer Wirkung einzuschränken. Wir sehen in allen drei Schichten Ausreisser, am wenigsten extrem in der Nacht. Sonst gibt es wenige Auffälligkeiten. Bleibt noch der Maschinentyp.
Code
ggplot(eda_data_500, aes(x = MachineType, y = CycleTime)) +geom_boxplot(fill ="lightblue") +labs(title ="Produktionszeiten nach Maschinentyp",x ="Maschinentyp",y ="CycleTime (Sekunden)" )
Hier wurden wieder alle Werte von CycleTime>500 vernachlässigt um die Boxen besser zu sehen. Maschinentyp B liegt bei tieferen Produktionszeiten, beide zeigen jedoch viele Werte über 200. Auch hier kein Rückschluss auf den Anstieg. Aber, wir wollen sehen, ob der “Knick” zu verschiedenen Lasten auftrit, je nach Maschinentyp. Dies ist ein side-by-side Boxplot, d.h. mehrere nebeneinander, z.B. für die verschiedenen Kategorien eine kategorialen Variable, wie hier des Maschinentyps.
Beide Maschinentypen folgen -bis auf wenige Ausreisser- der gleichen Abhängigkeit und der Knick erfolgt leicht oberhalb von 75%.
Kommen wir zur Diskussion und Interpretation, was wir aus der EDA bisher gelernt haben.
Diskussion und Interpretation
Histogramm und Boxplots: Aus dem Histogramm und den Boxplots haben wir gelernt, dass die Produktionszeiten ab ca. 75% Last den Grenzwert von 200s überschreiten, diese Phänomen aber weder von der Schicht oder dem Maschinentyp abhängt.
Streudiagramm Ab ca. 75% Last steigen die Produktionszeiten deutschlich schneller an als zwischen 0%-75%.
Wir wissen jetzt, dass wir uns auf diesen stärkeren Anstieg konzentrieren müssen um zu verstehen, wo die Ursache des Problems liegt.
Um ein tieferes Verständnis des Problems zu erlangen müssen wir die Variablen CycleTime und Load besser im Kontext verstehen. Dazu haben wir im Bereich der Fertigungstechnik recherchiert und aus der Literatur folgende Einsichten gewonnen.
In unserem Produktionsprozess ist CycleTimenicht nur die reine Bearbeitungszeit eines Werkstücks. Sie setzt sich zusammen aus
Genau deshalb ist die Variable Load hier entscheidend: Wir interpretieren Load als Auslastung der Maschine bzw. des Systems (wie „voll“ das System gerade ist).
Warum führt hohe Last zu stark steigenden CycleTimes?
Das ist ein klassischer Effekt aus der Warteschlangentheorie:
Bei niedriger Auslastung werden Werkstücke praktisch sofort bearbeitet. \(\Rightarrow\) Wartezeiten sind klein, CycleTime ist nahe an der Bearbeitungszeit.
Je näher die Auslastung an 100% kommt, desto häufiger müssen neue Werkstücke warten, weil die Maschine gerade beschäftigt ist. \(\Rightarrow\) Die Wartezeit wächst überproportional.
Die zentrale Einsicht lautet:
Wartezeiten steigen stark an, wenn die Auslastung hoch wird.
Anschaulich: Wenn eine Maschine „fast immer“ beschäftigt ist, reichen schon kleine Zufallsschwankungen (z. B. leicht längere Bearbeitungen einzelner Werkstücke), damit sich eine Schlange aufbaut – und diese Schlange baut sich nur langsam wieder ab.
Verbindung zu unserem Plot (der „Knick“)
Der sichtbare Knick ab ca. 75–80% Last passt genau zu dieser Logik:
Unterhalb dieser Schwelle ist die Wartezeit meist gering → CycleTime wächst nur moderat.
Oberhalb dieser Schwelle dominiert zunehmend die Wartezeit → CycleTime steigt deutlich schneller an, Warteschlangen entstehen.
Damit haben wir eine plausible Interpretation für das Muster aus der EDA: Die ungewöhnlich langen CycleTime-Werte sind sehr wahrscheinlich keine extrem langen Bearbeitungszeiten einzelner Werkstücke, sondern entstehen durch Wartezeiten im (fast) ausgelasteten System.
Empfehlung
Um das Auftreten der Warteschlangen zu verifizieren, sollten wir in der Produktion nach solchen Warteschlangen suchen. Z.B. Mitarbeiter befragen, ob sie Warteschlangen beobachten. Die Verlängerung der Produktionszeiten sind so hoch, dass Warteschlangen leicht identifiziert werden sollten. Wenn Warteschlangen das Problem sind, dann müssen die vorgelagerten Prozesschritte analysiert werden, ob diese zu viele Vorprodukte liefern oder es ist notwendig mehr Maschinen zu installieren um die einzelne Maschine unter 75% Last betreiben zu können.
Zusammenfassung
WichtigTakeaways: Was Sie aus diesem EDA-Start mitnehmen sollten
EDA-first: Wir starten mit echten Daten und visualisieren zuerst. Theorie holen wir on-demand, wenn sie zur Interpretation nötig ist.
Datenqualität ist Teil der Analyse: Datentypen korrekt setzen (kategorial vs. numerisch), Tippfehler bereinigen und fehlende Werte bewusst behandeln – sonst können Visualisierungen und Kennzahlen in die Irre führen.
Histogramm + Kennzahlen ergänzen sich:
Histogramme zeigen die Form der Verteilung, Kennzahlen machen sie quantitativ.
In unseren Daten ist Median < Mittelwert ⇒ die Verteilung ist rechtsschief (Ausreisser ziehen den Mittelwert nach oben).
Boxplot als kompakter Verteilungs-Check:
Quartile und IQR beschreiben die mittleren 50% der Daten und markieren Ausreisser pragmatisch über die 1.5·IQR-Regel. Damit sieht man schnell: „Was ist typisch?“ und „Was ist ungewöhnlich?“ .
Zentrale Erkenntnis im Beispiel:
Im Streudiagramm zeigt sich ein nichtlinearer Knick: Ab ca. 75–80% Last steigt CycleTime deutlich stärker an.
Interpretation im Kontext (Warteschlange): CycleTime ist im Prozess nicht nur Bearbeitungszeit, sondern \[
\text{CycleTime}=\text{Bearbeitungszeit}+\text{Wartezeit}.
\]Load interpretieren wir als Auslastung. Ein Effekt aus der Warteschlangentheorie erklärt den Knick: Wartezeiten steigen stark an, wenn die Auslastung hoch wird.
Die langen CycleTime-Werte sind damit plausibel als Wartezeiten im (fast) ausgelasteten System interpretierbar (nicht als „extrem lange Bearbeitung“ einzelner Werkstücke).
Empfehlung / nächster Schritt (vom Datenbild zur Realität):
Um die Warteschlangen-Hypothese zu verifizieren, sollten wir in der Produktion gezielt nach Warteschlangen suchen (z. B. Beobachtung vor Ort, Befragung der Mitarbeitenden).
Falls Warteschlangen tatsächlich die Ursache sind, sind zwei naheliegende Stellhebel:
vorgelagerte Prozessschritte so steuern, dass nicht dauerhaft „zu viel“ in die Maschine nachläuft,
Kapazität erhöhen, damit die Maschine typischerweise unter ~75% Last betrieben werden kann.
Abschliessende Bemerkung
Wir haben in dieser Einführung natürlich nicht alle Aspekte der EDA und der deskriptiven Statistik behandelt, aber viele der wichtigen Metriken und Visualisierungen kennengelernt. Wir werden dies in der Nachbreitung vertiefen.
Pragmatischen Vorgehen in der Praxis
Wir schliessen diese Einführung mit einer pragmatischen Checkliste, wie man sinnvoll in der Praxis an eine EDA herangeht. Sie ist in Anlehnung an das Buch zur EDA von Roger D. Peng [1] formuliert.
TippEDA-Checkliste
In der Praxis ist häufig sinnvoll in den nachfolgenden Schritten bei der EDA vorzugehen:
(Erste) Frage formulieren Was genau willst du wissen (möglichst konkret)?
Daten einlesen Daten in R laden (und dabei bereits erste Probleme notieren).